Decision Tree Classification
1 Imports
import graphviz from sklearn.tree import ( DecisionTreeClassifier, export_graphviz, ) from sklearn.model_selection import train_test_split from sklearn.datasets import load_breast_cancer
% matplotlib inline
2 The Data
cancer = load_breast_cancer() print(cancer.keys())
dict_keys(['DESCR', 'target_names', 'data', 'feature_names', 'target'])
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target)
3 The Model
def build_tree(max_depth=None): tree = DecisionTreeClassifier(max_depth=max_depth) tree.fit(X_train, y_train) print("Max Depth: {0}".format(max_depth)) print("Training Accuracy: {0:.2f}".format(tree.score(X_train, y_train))) print("Testing Accuracy: {0:.2f}".format(tree.score(X_test, y_test))) print() return build_tree()
Max Depth: None Training Accuracy: 1.00 Testing Accuracy: 0.93
It looks like the tree is overfitting the training data. This is because the default tree will have leaf nodes that match each case in the training data set. Limiting the depth of the tree will help with this.
for depth in range(1, 5): build_tree(depth)
Max Depth: 1 Training Accuracy: 0.92 Testing Accuracy: 0.90 Max Depth: 2 Training Accuracy: 0.95 Testing Accuracy: 0.92 Max Depth: 3 Training Accuracy: 0.96 Testing Accuracy: 0.92 Max Depth: 4 Training Accuracy: 0.98 Testing Accuracy: 0.91
The book was able to get 95% accuracy for the training data, although I don't seem to be able to do better than 92%.
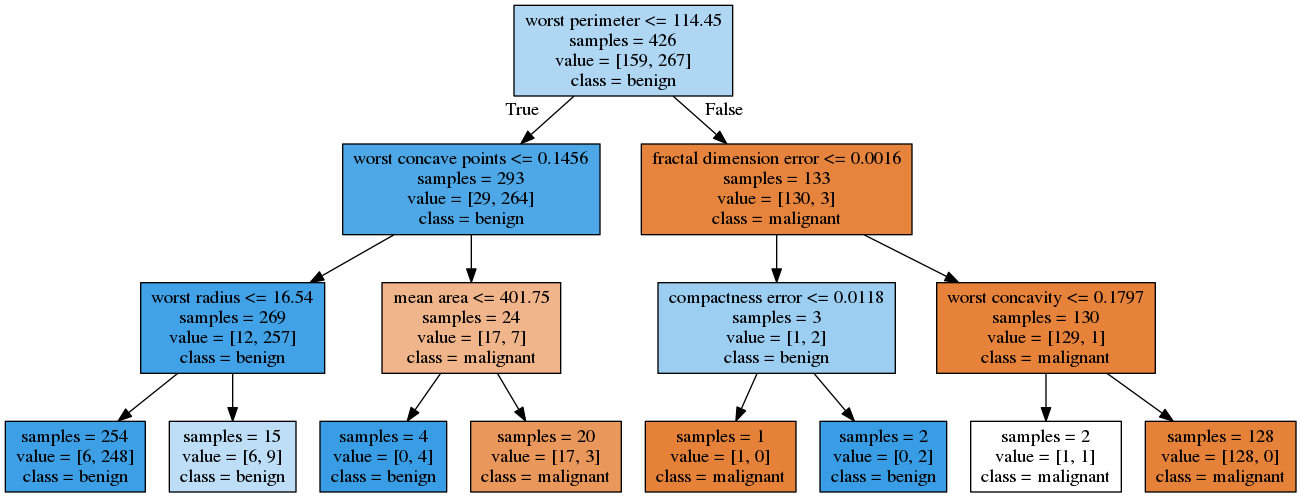
4 Visualizing The Tree
tree = DecisionTreeClassifier(max_depth=3) tree.fit(X_train, y_train) export_graphviz(tree, out_file="tree.dot", class_names=cancer.target_names, feature_names=cancer.feature_names, impurity=False, filled=True)
with open("tree.dot") as reader: dot_file = reader.read() graphviz.Source(dot_file, format="png").render("tree")