Python with Org-Babel
What is this about?
This is an initial look at how to use org-babel to create a literate-programming document. In the past I have used jupyter notebooks and pweave to do similar things, with each having a separate role - jupyter notebooks are good for interactive exploration but somewhat less amenable to working with sphinx (which I did with pweave). The hope here is that the org-babel system will provide something more amenable to both. Since you still have to convert the org-files to restructured text files (with pandoc or ox-nikola) it's still not everything I wanted, but hopefully this will make things a little easier
Most of this is stolen from this page - I'm fairly new to org-babel in general so I'm just walking in other people's footsteps for now.
Also, the inclusion of the org-babel code turned out to be both tedious and aesthetically unsatisfying so I didn't do it as much as I thought I would. The original org-file is here.
High-Level Module Structure
One nice thing about the org-babel/noweb system is that it has a system that makes it easy to create a template (in this case based on the the module structure from Code Like A Pythonista) with parts that we're updating inserted using the noweb syntax. To actually see this I had to include the python code as an org-mode snippet so the syntax highlighting isn't there.
#+begin_src python :noweb yes :tangle literate_python/literate.py
"""A docstring for the literate.py module"""
# imports
import sys
<<literate-main-imports>>
# constants
# exception classes
# interface funchtions
# classes
<<LiterateClass-definition>>
# internal functions & classes
<<literate-main>>
if __name__ == "__main__":
status = main()
sys.exit(status)
#+end_src
This is what the final file looks like once the no-web substitutions happen.
"""A docstring for the literate.py module"""
# imports
import sys
from argparse import ArgumentParser
# constants
# exception classes
# interface funchtions
# classes
class LiterateClass(object):
"""A class to be substituted above
Parameters
----------
String who: name of user
"""
def __init__(self, who):
self.who = who
return
def __call__(self):
print("Who: {0}".format(self.who))
# internal functions & classes
def main():
parser = ArgumentParser(description="literate caller")
parser.add_argument("-w", "--who", type=str,
default="me", help="who are you?")
args = parser.parse_args()
who = args.who
thing = LiterateClass(who)
thing()
return 0
if __name__ == "__main__":
status = main()
sys.exit(status)
To create the `literate.py` file (and all the other code-files) you see above execute M-x org-babel-tangle.
LiterateClass
This is the class definition that get substituted above. The code block for the definition is named LiterateClass-definition so the main template will substitute its contents for <<LiterateClass-definition>> when it gets tangled.
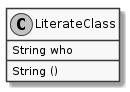
class LiterateClass(object):
"""A class to be substituted above
Parameters
----------
String who: name of user
"""
def __init__(self, who):
self.who = who
return
def __call__(self):
print("Who: {0}".format(self.who))
Main functions
The Code Like a Pythonista template expects that you are creating a command-line executable with a main entry-point. This section implements that case as an example.
First the <<literate-main-imports>>.
from argparse import ArgumentParser
Now the <<literate-main>>.
def main():
parser = ArgumentParser(description="literate caller")
parser.add_argument("-w", "--who", type=str,
default="me", help="who are you?")
args = parser.parse_args()
who = args.who
thing = LiterateClass(who)
thing()
return 0
As a quick check we can run the code at the command line to see that it's working (the main block has to be tangled for this to work).
python literate_python/literate.py --who "Not Me"
Who: Not Me
Testing
One nice thing about the org-babel infrastructure is that the tests and source can be put in the same org-file, then exported to separate files to be run.
Doctest
For the stdout output, doctesting can be a convenient way to check that things are behaving as expected while also providing an explicit example of how to run the command-line interface.
Setting up the cases
The output of a successful doctest is nothing, which is good for automated tests but less interesting here so I'll make a doctest that passes and one that should fail.
This next section (named literate-doctest) creates a code snippet that will pass.
example::
>>> from literate_python.literate import LiterateClass
>>> thing = LiterateClass("Gorgeous George")
>>> thing()
Who: Gorgeous George
And now here's a test (named literate-bad-doctest) that will fail.
bad::
>>> bad_thing = LiterateClass("Gorilla Glue")
>>> bad_thing()
Who: Magilla Gorilla
This next section will include the two doctests and export them to a file so they can be tested. Note that you need an empty line between the tests for both of them to run. Warning - since this file is going to be exported, if you are using nikola or some other system that assumes all files with a certain file-extension are blog-posts you have to use an extension that won't get picked up (in my case both rst and txt were interpreted as blog-posts).
#+begin_src text :noweb yes :tangle literate_python/test_literate_output.doctest :exports none
<<literate-doctest>>
<<literate-bad-doctest>>
#+end_src
Which gets tangled into this. Note that the doctests aren't valid python so you can tangle this but not execute it.
example::
>>> from literate_python.literate import LiterateClass
>>> thing = LiterateClass("Gorgeous George")
>>> thing()
Who: Gorgeous George
bad::
>>> bad_thing = LiterateClass("Gorilla Glue")
>>> bad_thing()
Who: Magilla Gorilla
Running the doctests
Now we can actually run them with python to see what happens.
python -m doctest literate_python/test_literate_output.doctest
true
**********************************************************************
File "literate_python/test_literate_output.doctest", line 9, in test_literate_output.doctest
Failed example:
bad_thing()
Expected:
Who: Magilla Gorilla
Got:
Who: Gorilla Glue
**********************************************************************
1 items had failures:
1 of 5 in test_literate_output.doctest
***Test Failed*** 1 failures.
Note that since this returned a non-zero exit code (I think) you need to put true in the code block or there would be no output.
PyTest BDD
While doctests are neat I prefer unit-testing, in particular using Behavior Driven Development (BDD) facilitated in this case by py.test and pytest_bdd.
The feature file
Identifying the code-block with #+begin_src feature adds some syntax highlighting (if you have feature-mode installed and set-up). This works both when you are in the external editor and in the main org-babel document as well.
To make sure that org-babel recognizes feature mode add this to the init.el file.
(add-to-list 'org-src-lang-modes '("feature" . "feature"))
This is what is going in the feature file.
Feature: Literate Class
Scenario: Creating a literate object
Given a name
When a Literate object is created with the name
Then the literate object has the name
The test file
This is another file that gets tangled out. In this case it is so that we can run py.test on it.
from expects import expect
from expects import equal
from pytest import fixture
from pytest_bdd import given
from pytest_bdd import scenario
from pytest_bdd import then
from pytest_bdd import when
# this code
from literate import LiterateClass
FEATURE_FILE = "literate.feature"
class Context(object):
"""context object"""
@fixture
def context():
return Context()
@scenario(FEATURE_FILE, "Creating a literate object")
def test_constructor():
return
@given("a name")
def add_name(context, faker):
context.name = faker.name()
@when('a Literate object is created with the name')
def create_object(context):
context.object = LiterateClass(context.name)
@then("the literate object has the name")
def check_object_name(context):
expect(context.name).to(equal(context.object.who))
return
Running the test
One important thing to note is that this will put an error message in a separate buffer if something goes wrong (like you don't have py.test installed), which in at least some cases makes it look like it failed silently. Unlike with the doctests, no output means something in the setup needs to be fixed, so you should tangle the file and then run it at the command-line to debug what happened.
py.test -v literate_python/testliterate.py
============================= test session starts ============================== platform linux -- Python 3.5.1+, pytest-3.0.5, py-1.4.32, pluggy-0.4.0 -- /home/cronos/.virtualenvs/nikola/bin/python3 cachedir: .cache rootdir: /home/cronos/projects/nikola/posts, iniimg-url: plugins: faker-2.0.0, bdd-2.18.1 collecting ... collected 1 items literate_python/testliterate.py::test_constructor PASSED =========================== 1 passed in 0.04 seconds ===========================
Getting This Into Nikola
I tried three ways to get this document into nikola:
ox-nikola worked (as did pandoc), but at the moment I'm trying to use the orgmode plugin so that I can keep editing this document without having to convert back and forth. This is turning out to be about the same amount of work as using jupyter (and with a steeper learning curve). But I like the folding and navigation that org-mode offers, so I'll stick with it for a bit. I'm just using the default set-up right now. It seems to work.
The main problem I had initially was the same one I had with jupyter - I'm starting with a file that wasn't generated by the nikola new_post sub-command so it didn't have the header that nikola expected but the only error nikola build reported was an invalid date format.
This is what needs to be at the top of the org-file for nikola to work with it (or something like it).
#+BEGIN_COMMENT
.. title: Python with Org-Babel
.. slug: python-with-org-babel
.. date: 2016-12-28 14:12:41 UTC-08:00
.. tags: howto python babel literateprogramming
.. category: how_to
.. link:
.. description:
.. type: text
#+END_COMMENT
The other thing is that the org-mode plugin doesn't seem to copy over the png-files correctly (or at all) so I had to create a files/posts/python-with-org-babel/literate_python folder and move the UML diagram over there by hand. Lastly, it didn't color the feature file and since there's no intermediate rst-file I don't really know how to fix this. Either I'm going to have to learn a lot more about org-mode than I might want to, or for cases where I want more control over things I'll use ox-nikola to convert it to rst first and edit it. That kind of wrecks the one-document idea, but I guess it would also give me a reason to re-work and polish things instead of improvising everything.