Dog Man


No meaning, just taking a line for a walk.
This post was created to see what happens in the slideshow if you put all the image files in the images folder without sub-folders, it's a companion to the Image Testing post.

If you want to just display the image they recommend you put it in the files folder, but you can still reference it in the images folder too, but you need to be aware of the fact that the folder path has to change. This org-reference:
[[img-url:../../images/bag-man.webp]]
Will include this (full-sized) image (note: The path to the images folder is based on where the post is, if the post was in a subfolder you'd have to go up three directories, not two).
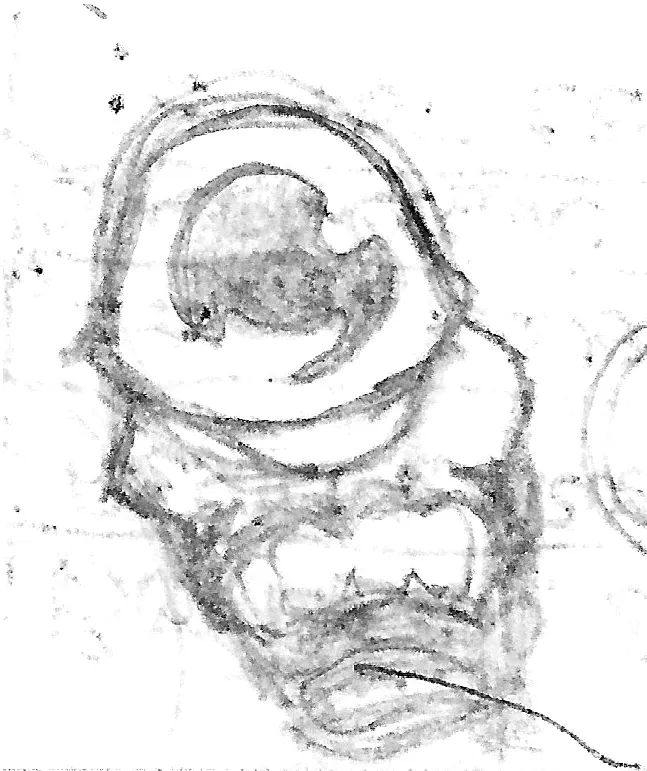
This was a tracing of the bag man onto kraft paper to mess around with gouache.

This is a look at using an embedded image from the images folder. If you put the files in the images folder then it automatically creates thumbnails and a slide-show, but there's a little trick to getting the folder references right.
If you use HTML you can just assume that the images folder is at the root of the site (make sure to set the class to "reference").
<a class="reference" href="/images/eyeball-man.webp" alt="Eyeball Man"><img src="/images/eyeball-man.thumbnail.webp"></a>
It took me a while to stumble upon this, but there is an image shortcode for those of us not using ReST (although it isn't directly linked to in the documentation for the ReST directive, from what I could tell). So if you want to do it the easier way:
images folder{{% thumbnail "/images/eyeball-man.webp" alt="Eyeball Man" title="Eyeball Man" %}}{{% /thumbnail %}}
This will give you a thumbnail which will produce a pop-up to the original image when it's clicked. In this case the original pencil doodle was about the size of the end of my thumb so there's no real yount to the pop-up. I just used the image to have something to experiment with.
alt attribute adds a title to the images in the slide show# python
from argparse import Namespace
from functools import partial
from pathlib import Path
# pypi
from bokeh.models import HoverTool
from selenium import webdriver
from tabulate import tabulate
import hvplot.pandas
import pandas
# others
from graeae import EmbedHoloviews
SLUG = "wikipedia-list-of-countries"
Embed = partial(EmbedHoloviews, folder_path=f"files/posts/{SLUG}")
Plot = Namespace(
width=990,
height=780,
fontscale=2,
)
This is just to make printing the pandas data-frames a little easier. emacs-jupyter actually does a pretty good job of rendering them as HTML like a regular jupyter notebook, but this makes it a little more readable while in emacs, plus I can control things better.
TABLE = partial(tabulate, showindex=False, tablefmt="orgtbl", headers="keys")
options = webdriver.FirefoxOptions()
options.headless = True
browser = webdriver.Firefox(firefox_options=options)
The tables are created using javascript so we need to use Selenium (or something else that handles javascript) to get the page for us.
URL = "https://www.wikiwand.com/en/List_of_countries_and_dependencies_by_population_density"
browser.get(URL)
Now we can let pandas convert the table to a data-frame. In this case there's multiple tables on the page but I only want the first one.
table = pandas.read_html(browser.page_source)[0]
print(TABLE(table.head(1)))
| ('Rank', 'Rank') | ('Country (or dependent territory)', 'Country (or dependent territory)') | ('Area', 'km2') | ('Area', 'mi2') | ('Population', 'Population') | ('Density', 'pop./km2') | ('Density', 'pop./mi2') | ('Date', 'Date') | ('Population source', 'Population source') |
|--------------------+----------------------------------------------------------------------------+-------------------+-------------------+--------------------------------+---------------------------+---------------------------+--------------------+----------------------------------------------|
| – | Macau (China) | 115.3 | 45 | 696100 | 21158 | 54799 | September 30, 2019 | Official quarterly estimate |
That kind of worked but the column names are odd, and I don't want all of them anyway so I'll fix that.
table.columns = [column[0] for column in table.columns]
print(TABLE(table.head(1)))
| Rank | Country (or dependent territory) | Area | Area | Population | Density | Density | Date | Population source |
|---|---|---|---|---|---|---|---|---|
| – | Macau (China) | 115.3 | 45 | 696100 | 21158 | 54799 | September 30, 2019 | Official quarterly estimate |
Now, I messed up the units for area and density, but I'm not good with the metric system and Density is a calculated column anyway, so maybe I should get rid of some columns to make it easier.
Columns = Namespace(
rank="Rank",
date="Date",
source="Population source",
area="Area (square miles)",
area_cleaned = "Area",
density="Density (population/square miles)",
density_cleaned = "Density",
country="Country (or dependent territory)",
country_cleaned = "Country",
population="Population",
)
columns = list(table.columns)
columns[2] = "remove"
columns[3] = Columns.area
columns[5] = "remove2"
columns[6] = Columns.density
table.columns = columns
del(table["remove"])
del(table["remove2"])
print(TABLE(table.head(1)))
| Rank | Country (or dependent territory) | Area (square miles) | Population | Density (population/square miles) | Date | Population source | |--------+------------------------------------+-----------------------+--------------+-------------------------------------+--------------------+-----------------------------| | – | Macau (China) | 45 | 696100 | 54799 | September 30, 2019 | Official quarterly estimate |
I guess because the table is so long Wikipedia repeats the header at the bottom of the table.
print(TABLE(table.iloc[-2:]))
| Rank | Country (or dependent territory) | Area (square miles) | Population | Density (population/square miles) | Date | Population source |
|---|---|---|---|---|---|---|
| Rank | Country (or dependent territory) | mi2 | Population | pop./mi2 | Date | Population source |
| Rank | Country (or dependent territory) | Area | Population | Density | Date | Population source |
So we have to remove them and also convert the numeric columns to numeric types since pandas had to render them all as objects (strings).
table = table.iloc[:-2]
print(TABLE(table.iloc[-2:]))
| Rank | Country (or dependent territory) | Area (square miles) | Population | Density (population/square miles) | Date | Population source |
|---|---|---|---|---|---|---|
| – | Svalbard and Jan Mayen (Norway) | 23706 | 2655 | 0.1 | September 1, 2012 | Official estimate |
| – | Greenland (Denmark) | 836297 | 55877 | 0.08 | January 1, 2018 | Official estimate |
I'm guessing that there's no fractional populations, but if you look at the areas some of them are non-integers.
print(table[Columns.area].min())
0.19
So only the population is an integer (I'm assuming).
for column in [Columns.area, Columns.density]:
table[column] = table[column].astype(float)
table[Columns.population] = table[Columns.population].astype(int)
This is just to take a look.
First I'll sort the table by area using sort_values.
plotter = table.sort_values(by=Columns.area)
plotter = plotter.rename(columns={
Columns.area: Columns.area_cleaned,
Columns.density: Columns.density_cleaned,
Columns.country: Columns.country_cleaned,
})
country = f"@{Columns.country_cleaned}"
population = f"@{Columns.population}{{0,0}}"
density = f"@{{{Columns.density_cleaned}}}"
area = f"@{Columns.area_cleaned}{{0,0.00}} (Square Miles)"
hover = HoverTool(tooltips=[
("Country", country),
("Area", area),
("Population", population),
("Density", density)
])
plot = plotter.hvplot.barh(x=Columns.country_cleaned,
y=Columns.area_cleaned,
hover_cols=[
Columns.population,
Columns.density_cleaned
]).opts(
title="Countries by Area",
width=Plot.width,
height=Plot.height * 2,
tools=[hover],
)
outcome = Embed(plot=plot, file_name="countries_by_area")()
print(outcome)
Well, that's not so easy to read. Maybe just the top and bottom ten.
subset = plotter.iloc[-10:]
plot = subset.hvplot.barh(x=Columns.country_cleaned, y=Columns.area_cleaned,
hover_cols=[Columns.population,
Columns.density_cleaned]).opts(
title="Top Ten Countries by Area",
width=Plot.width,
height=Plot.height,
fontscale=Plot.fontscale,
xrotation=45,
tools=[hover],
)
outcome = Embed(plot=plot, file_name="top_ten_countries_by_area")()
print(outcome)
So, this shows us a few things to fix. One, the first row is likely just the sum of the others, I would think… But even if it isn't it's so big that it kind of throws stuff off. Also we could probably suck out Antarctica from the second row to make the table match the one Wikipedia has of just countries by area.
The other thing is that there are reference to notes that I don't know that I want.
numeric = [Columns.area_cleaned, Columns.population, Columns.density_cleaned]
columns={
Columns.area: Columns.area_cleaned,
Columns.density: Columns.density_cleaned,
Columns.country: Columns.country_cleaned,
}
world = plotter.iloc[-1][numeric]
without_antarctica = plotter.iloc[-2][numeric]
antarctica = world - without_antarctica
antarctica[Columns.rank] = "-"
antarctica[Columns.country] = "Antarctica"
antarctica[Columns.date] = plotter[Columns.date].iloc[-1]
antarctica[Columns.source] = plotter[Columns.source].iloc[-1]
antarctica = antarctica.rename(columns)
antarctica = antarctica[plotter.columns]
cleaned = plotter.iloc[:-2]
cleaned = cleaned.append(antarctica, ignore_index=True)
cleaned = cleaned.rename(columns=columns)
print(antarctica)
Rank - Country Antarctica Area 5.41e+06 Population 0 Density -14 Date September 19, 2020 Population source USCB's World population clock dtype: object
print(f"Area Difference: {world[Columns.area_cleaned] - cleaned[Columns.area_cleaned].sum():,.2f}")
print(f"Population Difference: {world[Columns.population] - cleaned[Columns.population].sum():,}")
Area Difference: -554,000.57 Population Difference: 168,435,684
So, it doesn't actually match the way I thought. I guess there are parts of the world that aren't part of a country… That's a huge difference in population, though… I'll have to investigate that separately.
For some reason pandas is acting up here so I had to separate the building of the dataframe and re-running the code blocks a few times. It even said that pandas couldn't find html5lib, which is kind of weird since the earlier read_html call worked…
URL = "https://www.wikiwand.com/en/List_of_countries_and_dependencies_by_population"
browser.get(URL)
Now that I think about it, maybe it takes some time for the javascript to render so you need to have a pause, especially if the internet connection is acting up.
tables = pandas.read_html(browser.page_source)
by_population = tables[1]
print(TABLE(by_population.head(1)))
| Rank | Country(or dependent territory) | Population | % of world | Date | Source(official or UN) |
|---|---|---|---|---|---|
| 1 | China[b] | 1404513080 | nan | 20 Sep 2020 | National population clock[3] |
Pandas doesn't seem to be able to handle the "% of world" column - probably because they put the percent symbol in the rows for some reason.
population_2 = by_population[Columns.population].sum()
print(f"{world[Columns.population] - population_2:,}")
print(f"{cleaned[Columns.population].sum() - population_2:,}")
-7,693,448,437 -7,861,884,121
What?
print(f"{population_2:,}")
15,507,529,605
According to the Wikipedia page the world population is 7,814,267,000 - so something isn't right here.
print(len(by_population))
print(len(cleaned))
242 252
They also don't have the same number of countries (it should be off by 1 because of Antarctica, not by 10).
countries = set(cleaned[Columns.country_cleaned])
# the new table doesn't have a space between Country and the parenthesis
countries_2 = set(by_population["Country(or dependent territory)"])
print(countries - countries_2)
print()
print(countries_2 - countries)
{'Northern Cyprus[note 4]', 'Western Sahara[note 12]', 'Taiwan', 'British Virgin Islands (United Kingdom)', 'Morocco', 'Bonaire (Netherlands)', 'Jersey (United Kingdom)', 'Cyprus', 'Anguilla (United Kingdom)', 'Isle of Man (United Kingdom)', 'Russia[note 11]', 'Wallis & Futuna (France)', 'Saba (Netherlands)', 'United States', 'Transnistria[note 3]', 'Vatican City[note 1]', 'Somaliland[note 8]', 'United States Virgin Islands (United States)', 'France', 'Turks and Caicos Islands (United Kingdom)', 'Cook Islands (New Zealand)', 'Democratic Republic of the Congo', 'Mayotte (France)', 'Tanzania', 'China', 'Guam (United States)', 'Falkland Islands (United Kingdom)', 'Guernsey (United Kingdom)', 'Northern Mariana Islands (United States)', 'Netherlands', 'Serbia', 'Republic of the Congo', 'Pitcairn Islands (United Kingdom)', 'Timor-Leste', 'Kosovo[note 2]', 'Eswatini (Swaziland)', 'Niue (New Zealand)', 'Denmark', 'Gibraltar (United Kingdom)', 'Saint Helena, Ascension and Tristan da Cunha (United Kingdom)', 'Finland', 'Pakistan', 'American Samoa (United States)', 'Sint Eustatius (Netherlands)', 'Bermuda (United Kingdom)', 'India', 'Abkhazia[note 6]', 'United Kingdom', 'Cayman Islands (United Kingdom)', 'Puerto Rico (United States)', 'Moldova', 'French Guiana (France)', 'South Ossetia[note 9]', 'Guadeloupe (France)', 'Ukraine [note 5]', 'Georgia', 'Svalbard and Jan Mayen (Norway)', 'Somalia', 'Tokelau (New Zealand)', 'Réunion (France)', 'Uruguay[note 7][clarification needed]', 'Martinique (France)', 'Federated States of Micronesia', 'Montserrat (United Kingdom)', 'Artsakh[note 10]', 'Antarctica'}
{'Pakistan[e]', 'India[c]', 'DR Congo', 'Falkland Islands (UK)', 'United Kingdom[h]', 'Wallis and Futuna (France)', 'Puerto Rico (US)', 'East Timor', 'Republic of Artsakh[z]', 'China[b]', 'Taiwan[l]', 'South Ossetia[aa]', 'Tokelau (NZ)', 'World', 'Ukraine[j]', 'Netherlands[m]', 'Saint Helena, Ascensionand Tristan da Cunha (UK)', 'American Samoa (US)', 'Tanzania[i]', 'Finland[q]', 'Vatican City[ab]', 'U.S. Virgin Islands (US)', 'Morocco[k]', 'Transnistria[w]', 'Somalia[n]', 'Abkhazia[y]', 'Cayman Islands (UK)', 'Gibraltar (UK)', 'Serbia[o]', 'Uruguay', 'Cook Islands (NZ)', 'Northern Cyprus[x]', 'Eswatini', 'Guernsey (UK)', 'Congo', 'Russia[f]', 'Bermuda (UK)', 'Pitcairn Islands (UK)', 'Guam (US)', 'Montserrat (UK)', 'Moldova[s]', 'Kosovo[t]', 'Denmark[p]', 'Jersey (UK)', 'France[g]', 'Isle of Man (UK)', 'Cyprus[u]', 'Anguilla (UK)', 'Georgia[r]', 'Western Sahara[v]', 'Northern Mariana Islands (US)', 'F.S. Micronesia', 'United States[d]', 'Turks and Caicos Islands (UK)', 'Niue (NZ)', 'British Virgin Islands (UK)'}
Some of that is just their notes being added, and an inconsistency of naming, e.g. United Kingdom vs UK. but the population only set also seems to break up things a little differently - they consider the countries within the Netherlands to be separate, for instance. This is messier than I thought, and I don't know how to reconcile the population explosion.
Okay, I just noticed something.
print(TABLE(by_population.tail(1)))
| Rank | Country(or dependent territory) | Population | % of world | Date | Source(official or UN) |
|---|---|---|---|---|---|
| nan | World | 7814267000 | 100% | 19 Sep 2020 | UN Projection[202] |
They copied the header here too, but pandas was able to parse the numbers (probably because the headers only have one row).
world_2 = by_population.iloc[-1]
by_population = by_population[:-1]
population_2 = by_population[Columns.population].sum()
print(f"{world[Columns.population] - population_2:,}")
print(f"{cleaned[Columns.population].sum() - population_2:,}")
print(f"{population_2:,}")
121,019,395 -47,416,289 7,693,262,605
The second table is short too, but it still has more than the original table… Maybe I just don't care about the numbers, as long as they're rankable. Although the fact that the tables have different numbers of countries isn't reassuring…
I think I'll see if making a combined table myself would be better. But first let's see what percentage of the population is missing.
print(f"By Population Table: {(by_population.Population/world_2.Population).sum() * 100:0.2f} %")
print(f"By Density Table: {(cleaned.Population/world_2.Population).sum() * 100:0.2f} %")
By Population Table: 98.45 % By Density Table: 97.84 %
URL = "https://www.wikiwand.com/en/List_of_countries_and_dependencies_by_area"
browser.get(URL)
tables = pandas.read_html(browser.page_source)
by_area = tables[0]
print(TABLE(by_area.head(1)))
| Rank | Country / Dependency | Total in km2 (mi2) | Land in km2 (mi2) | Water in km2 (mi2) | % water | Notes |
|---|---|---|---|---|---|---|
| nan | World | 510,072,000 (196,940,000) | 148,940,000 (57,510,000) | 361,132,000 (139,434,000) | 70.8 | nan |
So once again we have a summation in there, but we have a bigger problem in that they combine the units in the same columns…
print(len(by_area))
264
Okay, so now we have another problem in that all three sets have differing numbers of entries. I'm guessing that trying to reconcile the country names is going to be a nightmare so I think I'll have to stick with the original table. I just looked at the Wikipedia page and this table includes "unrecognized states" which is probably why it has more countries. Maybe it's these unrecognized states that makes up the shortcoming in the population and area. Maybe.
cleaned = cleaned.sort_values(by=Columns.area_cleaned)
subset = cleaned.iloc[-10:]
plot = subset.hvplot.barh(x=Columns.country_cleaned, y=Columns.area_cleaned,
hover_cols=[Columns.population,
Columns.density_cleaned]).opts(
title="Top Ten Countries by Area",
width=Plot.width,
height=Plot.height,
fontscale=Plot.fontscale,
tools=[hover],
xrotation=45,
)
outcome = Embed(plot=plot, file_name="top_ten_countries_by_area_cleaned")()
print(outcome)
Okay, so it looks like I forgot to clean out the note references in the country names. Also, Russia as bigger than Antarctica? Go figure. I'm also surprised that the United States has more area than China. Actually I was surprised by this whole thing. I guess I never really looked too closely at the relative sizes of countries before, and area's a tough thing to estimate visually.
names = cleaned[Columns.country_cleaned].str.split("[", expand=True)[0]
cleaned[Columns.country_cleaned] = names
subset = cleaned.sort_values(by=Columns.area_cleaned, ascending=False).iloc[-10:]
plot = subset.hvplot.barh(x=Columns.country_cleaned, y=Columns.area_cleaned).opts(
title="Bottom Ten Countries by Area",
width=Plot.width,
height=Plot.height,
fontscale=Plot.fontscale,
)
outcome = Embed(plot=plot, file_name="bottom_ten_countries_by_area_cleaned")()
print(outcome)
subset = cleaned.sort_values(by=Columns.population).iloc[-10:]
population_columns = [Columns.area_cleaned,
Columns.density_cleaned]
plot = subset.hvplot.barh(x=Columns.country_cleaned, y=Columns.population,
hover_cols=population_columns).opts(
title="Top Ten Countries by Population",
width=Plot.width,
height=Plot.height,
fontscale=Plot.fontscale,
tools=[hover],
xrotation=45,
)
outcome = Embed(plot=plot, file_name="top_ten_countries_by_population")()
print(outcome)
I had encountered this list before, when reading Memory Craft by Lynne Kelly, but it still surprises me that the United States is third and that Bangladesh has more people than Russia.
subset = cleaned.sort_values(by=Columns.population, ascending=False).iloc[-10:]
plot = subset.hvplot.barh(x=Columns.country_cleaned, y=Columns.population,
hover_cols=population_columns).opts(
title="Bottom Ten Countries by Population",
width=Plot.width,
height=Plot.height,
fontscale=Plot.fontscale,
tools=[hover],
)
outcome = Embed(plot=plot, file_name="bottom_ten_countries_by_population")()
print(outcome)
density_columns=[Columns.population, Columns.area_cleaned]
subset = cleaned.sort_values(by=Columns.density_cleaned).iloc[-10:]
plot = subset.hvplot.barh(x=Columns.country_cleaned, y=Columns.density_cleaned,
hover_cols=density_columns).opts(
title="Top Ten Countries by Population Density",
width=Plot.width,
height=Plot.height,
fontscale=Plot.fontscale,
tools=[hover],
)
outcome = Embed(plot=plot, file_name="top_ten_countries_by_population_density")()
print(outcome)
It's sort of interesting that the two most dense countries are both known for their gambling.
First, because of the way I calculated Antarctica it currently has a negative number (-14) for density, which is a little odd so I'll set it to 0.
cleaned.loc[cleaned[Columns.country_cleaned]=="Antarctica", Columns.density_cleaned] = 0
subset = cleaned.sort_values(by=Columns.density_cleaned, ascending=False).iloc[-10:]
plot = subset.hvplot.barh(x=Columns.country_cleaned, y=Columns.density_cleaned,
hover_cols=density_columns).opts(
title="Bottom Ten Countries by Population Density",
width=Plot.width,
height=Plot.height,
fontscale=1.5,
tools=[hover],
yrotation=45,
)
outcome = Embed(plot=plot, file_name="bottom_ten_countries_by_population_density")()
print(outcome)
Well, the point wasn't really just to look at the list (there is a Wikipedia page there already, after all) but to have something that I could mess with locally, so I'll save it now, but first I'll do a little more cleaning.
Do I need the rank? Nah.
del(cleaned[Columns.rank])
I was going to remove the density and re-calculate it but for some reason they don't differ that much, but it might make a difference in the rankings for less dense countries so I'll keep the original column.
Since I'm going to save it to a csv I'll parse the date first.
cleaned[Columns.date] = pandas.to_datetime(cleaned[Columns.date])
Even though the table is meant for population density I think I'll save it sorted by area.
cleaned = cleaned.sort_values(by=Columns.area_cleaned, ascending=False)
And now to save it.
path = Path("apeiron/wikipedia")
assert path.is_dir()
cleaned.to_csv(path/"countries-by-area-population-density.csv", index=False)
In the time of boar and Monkey,
When Death became a painter,
Love forgot its mother's name,
And new memories burn fainter.
Sitting on the front porch,
Eating screaming greens,
We sang a song of six-fingers,
In unkown Cantonese.
Down on the mountain,
Riding to the Top,
Father rode side-saddle,
The Other rode to crop.
Covid came for cannabis,
And stayed around for meth,
Our planet burned around us,
While Juniors breathed out death.
The rage didn't kill us,
It had no monopoly,
I watched it all through opaque glass,
Looking out for me.
Still the Rabbit sits backwards-look-away
Muttering her grumbles,
Through her dark of day,
And the Spiders sing around my head -
"We will never go away."
# python
from functools import partial
# pypi
import hvplot.pandas
import pandas
import requests
from graeae import EmbedHoloviews
SLUG = "pulling-top-100-names"
Embed = partial(EmbedHoloviews, folder_path=f"files/posts/{SLUG}")
URL = "https://www.ssa.gov/OACT/babynames/decades/century.html"
response = requests.get(URL)
assert response.ok
tables = pandas.read_html(response.text)
print(len(tables))
1
table = tables[0]
print(table.head(1))
Unnamed: 0_level_0 Males Females
Rank Name Number Name Number
0 1.0 James 4764644 Mary 3328565
So it looks like it's a plain table so we don't need Selenium or something else to render javascript, but the header is a little messed up.
males = table[table.columns[1:3]]
females = table[table.columns[3:]]
print(males.head(1))
Males
Name Number
0 James 4764644
print(males.iloc[-1])
Males Name Source: 100% sample based on Social Security c...
Number Source: 100% sample based on Social Security c...
Name: 100, dtype: object
print(table.tail(1)[table.columns[-1]].values[0])
Source: 100% sample based on Social Security card application data as of of March 2019. See the limitations of this data source.
That's interesting, but it doesn't help with what I want, which is just the names.
males = males.iloc[:-1]
females = females.iloc[:-1]
assert len(males) == 100
assert len(females) == 100
print(females.head(1))
Females
Name Number
0 Mary 3328565
So, now to re-add the rank and add gender columns so the multi-level column headers can be re-done.
males.columns = ["name", "count"]
females.columns = ["name", "count"]
males["gender"] = "male"
females["gender"] = "female"
males["rank"] = list(range(1, 101))
females["rank"] = list(range(1, 101))
print(males.head(1))
name count gender rank
0 James 4764644 male 1
Now to re-combine them.
names = pandas.concat([males, females])
Before we can plot them we have to change the count column to be (you guessed it) a number since that last row with the source information prevents pandas' ability to convert the column itself.
names.loc[:, "count"] = names["count"].astype(int)
plot = names.hvplot.bar(x="rank", y="count", by="gender").opts(
title="Top Male and Female Names of the Last 100 Years",
width=990,
height=780,
fontscale=2,
)
outcome = Embed(plot=plot, file_name="gender_plot")()
print(outcome)
Well, pretend that you don't see the x-ticks… It's interesting that the highest ranked male names have a higher count than the highest ranked female names.
Time to save the table.
names.to_csv("apeiron/top_100_ssa_names.csv", index=False)
# python
from argparse import Namespace
from functools import partial
import re
# pypi
from bs4 import BeautifulSoup, UnicodeDammit
from selenium import webdriver
from tabulate import tabulate
import pandas
TABLE = partial(tabulate, headers="keys", tablefmt="orgtbl", showindex=False)
I'll use a headless instance of selenium-firefox to grab and render the wikipedia page.
options = webdriver.FirefoxOptions()
options.headless = True
browser = webdriver.Firefox(firefox_options=options)
URL = "https://en.wikipedia.org/wiki/List_of_legendary_creatures_by_type"
browser.get(URL)
This page is a little odd in that it uses tables but the tables then contain unordered lists which seem to give pandas a hard time, so I'll have to poke around a little bit using Beautiful Soup first to figure it out.
soup = BeautifulSoup(browser.page_source)
The level-2 headlines describe different ways to catalog the creatures, in addition they have "span" tags within them that have the "mw-class" associated with them so we can grab those tags using Beautiful Soup's select method, which uses CSS selectors.
headlines = soup.select("h2 span.mw-headline")
for headline in headlines:
print(f" - {headline}")
We don't need references, but the other headlines might be helpful in categorizing these animals. Unfortunately the headings are above the sections with the stuff we want - they aren't parents of the sections so to get the actual parts we're going to need to do something else.
I'll grab all the tables then filter out the ones I don't want - the first three tables are admonitions that the page might not be up to snuff and the last four are references and links to other pages.
tables = soup.find_all("table")
tables = tables[3:-4]
print(len(tables))
Table = Namespace(
aquatic=0,
arthropods=1,
bears=2,
)
PATTERN = "\w+"
WEIRD = "\xa0"
ERASE = ""
table = tables[Table.aquatic]
items = table.find_all("li")
DASH = items[0].text[23]
animals = []
origin = []
description = []
for item in items:
text = item.text.replace(WEIRD, ERASE)
text = text.replace(DASH, ERASE)
tokens = text.split(" (")
two_tokens = tokens[1].split(")")
animals.append(tokens[0].strip())
origin.append(two_tokens[0].strip())
description.append(two_tokens[1].strip())
beasts = pandas.DataFrame.from_dict(dict(
animal=animals,
origin=origin,
description=description))
beasts["type"] = "Aquatic"
print(TABLE(beasts))
| animal | origin | description | type |
|---|---|---|---|
| Bake-kujira | Japanese | ghost whale | Aquatic |
| Ceffyl Dŵr | Welsh | water horse | Aquatic |
| Encantado | Brazil | shapeshifting trickster dolphins | Aquatic |
| Kelpie | Scottish | water horse | Aquatic |
| Kushtaka | Tlingit | shapeshifting "land otter man" | Aquatic |
| Selkie | Scottish | shapeshifting seal people | Aquatic |
table = tables[Table.arthropods]
animal = []
origin = []
description = []
for item in table.find_all("li"):
first, last = item.text.split("(")
second, third = last.split(f"{WEIRD}{DASH} ")
first = first.strip()
second = second.replace(")", ERASE).strip()
third = third.strip()
animal.append(first)
origin.append(second)
description.append(third)
to_append = pandas.DataFrame.from_dict(
dict(
animal=animal,
origin=origin,
description=description
)
)
to_append["type"] = "Arthropod"
beasts = pandas.concat([beasts, to_append])
print(TABLE(to_append))
| animal | origin | description | type |
|---|---|---|---|
| Anansi | West African | trickster spider | Arthropod |
| Arachne | Greek | weaver cursed into a spider | Arthropod |
| Khepri | Ancient Egyptian | beetle who pushes the sun | Arthropod |
| Tsuchigumo | Japanese | shapeshifting giant spider | Arthropod |
| Myrmecoleon | Christian | ant-lion | Arthropod |
| Myrmidons | Greek | warriors created from ants by Zeus | Arthropod |
| Jorōgumo | Japanese | ghost woman who shapeshifts into a spider | Arthropod |
| Karkinos | Greek | Cancer the crab | Arthropod |
| Mothman | American cryptid | man with moth wings and features | Arthropod |
| Pabilsag | Babylonian | Sagittarius-like creature with scorpion tail | Arthropod |
| Scorpion man | Babylonian | protector of travellers | Arthropod |
| Selket | Ancient Egyptian | scorpion death/healing goddess | Arthropod |
table = tables[Table.bears]
animal, origin, description = [], [], []
for item in table.find_all("li"):
first, right = item.text.split("(")
second, third = right.split(f"){WEIRD}{DASH} ")
animal.append(first)
origin.append(second)
description.append(third)
to_append = pandas.DataFrame.from_dict(
dict(animal=animal,
origin=origin,
description=description)
)
beasts = pandas.concat([beasts, to_append], ignore_index=True)
print(TABLE(to_append))
| animal | origin | description |
|---|---|---|
| Bugbear | Celtic | child-eating hobgoblin |
| Callisto | Greek | A nymph who was turned into a bear by Hera. |
As part of my pursuit of randomness I'm creating lists of things to select from. In this case I wanted a list of animals to create a Visual Alphabet and I decided to grab one from wikipedia. This is what I did.
# python
from functools import partial
from pathlib import Path
from string import ascii_uppercase
import os
import re
# pypi
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from expects import (
be_true,
expect,
)
from selenium import webdriver
from tabulate import tabulate
import pandas
This is just to make printing the pandas data-frames a little easier. emacs-jupyter actually does a pretty good job of rendering them as HTML like a regular jupyter notebook, but this makes it a little more readable while in emacs, plus I can control things better.
TABLE = partial(tabulate, showindex=False, tablefmt="orgtbl", headers="keys")
I started this using Requests-HTML because wikipedia uses JQuery to render the tables and Requests-HTML it uses pyppeteer to render javascript (as opposed to the reqular requests that just does an HTTP GET and so leaves the tables un-rendered). Unfortunately I can't get it to work in a jupyter notebook. One problem is that both jupyter and Requests-HTML use asyncio - using nest_asyncio allows pypeteer to run in the notebook but then I get this error:
AttributeError: 'coroutine' object has no attribute 'newPage'
Which looks like it might be a pypeteer error, but tracking all this down is taking too long so I'm going to switch to using selenium. Since I'm running this on a remote machine we have to run it headless. I used to do this using XVFB but selenium has a headless mode so I'll try that instead.
options = webdriver.FirefoxOptions()
options.headless = True
browser = webdriver.Firefox(firefox_options=options)
Just let selenium render the JQuery tables for us.
URL = "https://en.wikipedia.org/wiki/List_of_animal_names"
browser.get(URL)
After giving up on Requests-HTML I was using Beautiful Soup to pull out the table so I could give it to pandas, but then I looked at the pandas documentation and it turns out they already do this, so you don't need to, but you do need to know how many tables there are and which one you want (it returns a list of dataframes). In this case I want the last one.
table = pandas.read_html(browser.page_source)[-1]
print(TABLE(table.head(1)))
| ('Animal', 'A') | ('Young', 'A') | ('Female', 'A') | ('Male', 'A') | ('Collective noun', 'A') | ('Collateral adjective', 'A') | ('Culinary noun for meat', 'A') |
|---|---|---|---|---|---|---|
| Aardvark | cub | sow | boar | nan | orycteropodian | nan |
That's a little odd looking.
First, what's with all the A entries in the header?
print(table.columns)
MultiIndex([( 'Animal', 'A'),
( 'Young', 'A'),
( 'Female', 'A'),
( 'Male', 'A'),
( 'Collective noun', 'A'),
( 'Collateral adjective', 'A'),
('Culinary noun for meat', 'A')],
)
Hmm..
table.columns = [column[0] for column in table.columns]
print(table.columns)
Index(['Animal', 'Young', 'Female', 'Male', 'Collective noun',
'Collateral adjective', 'Culinary noun for meat'],
dtype='object')
print(TABLE(table.head(1)))
| Animal | Young | Female | Male | Collective noun | Collateral adjective | Culinary noun for meat |
|---|---|---|---|---|---|---|
| Aardvark | cub | sow | boar | nan | orycteropodian | nan |
At this point I don't know what I really want to do with this. I was originally going to just save the animal names but now the other stuff looks kind of interesting. As an aside I had to look up Collateral Adjective on wikipedia:
A collateral adjective is an adjective that is identified with a particular noun in meaning, but that is not derived from that noun.
Good to know.
meats = table.dropna(subset=["Culinary noun for meat"])
print(len(meats))
49
So, now I noticed something else wrong.
print(TABLE(meats.iloc[-1:]))
| Animal | Young | Female | Male | Collective noun | Collateral adjective | Culinary noun for meat |
|---|---|---|---|---|---|---|
| Z | Z | Z | Z | Z | Z | Z |
Oops. Maybe I should have looked at the table more closely.
Let's see if using Beautiful Soup will help clean up the dataset a little.
soup = BeautifulSoup(browser.page_source)
soup_table = soup.find_all("table")[-1]
The read_html method always returns a list, even though I'm only passing in one table.
table = pandas.read_html(str(soup_table))[0]
print(TABLE(table.iloc[-1:]))
| ('Animal', 'A') | ('Young', 'A') | ('Female', 'A') | ('Male', 'A') | ('Collective noun', 'A') | ('Collateral adjective', 'A') | ('Culinary noun for meat', 'A') |
|---|---|---|---|---|---|---|
| Zebra | foal colt (male) filly (female) | mare | stallion | herd[11][107] cohort[107]dazzle [108] zeal[11][107] | zebrine hippotigrine | nan |
Actually, that looks worse.
I went back and looked at the page and the table is broken up by sub-headers indicating the first letter of the animal's name.
print(str(soup_table).split("\n")[10])
<th colspan="7"><span id="A"></span><b>A</b>
So, maybe I can clean that up a little before creating the table - here's where Beautiful Soup comes in. First I'll find all the tags whose ID matches a letter of the alphabet and then I'll use the decompose method to destroy the grand-parent of that tag - decompose destroys both the tag it's called on and all the descendants of that tag so this will destroy the grand-parent (table-row tag), parent (table-header) and matching tag (span with the ID matching the letter) and it's child (the bold tag). I'm also calling smooth and encode to clean the tree up once the tags are destroyed, although, to be honest, I don't know if that's really needed here, it just seemed like a good idea.
for character in ascii_uppercase:
element = soup_table.find(id=character)
if element is None:
print(f"Element for {character} not found")
else:
element.parent.parent.decompose()
soup_table.smooth()
soup_table.encode()
table = pandas.read_html(str(soup_table))[0]
print(TABLE(table.head(1)))
| Animal | Young | Female | Male | Collective noun | Collateral adjective | Culinary noun for meat |
|---|---|---|---|---|---|---|
| Aardvark | cub | sow | boar | nan | orycteropodian | nan |
So, now our first row is for Aardvark instead of the letter A. And now back to the meats.
meats = table.dropna(subset=["Culinary noun for meat"])
print(len(meats))
24
There are twenty-four entries in our table that have a noun referring to the animal as meat. Let's see what they are.
meats = meats.rename(columns={"Culinary noun for meat": "Meat"})
for row in meats.itertuples():
print(f"{row.Animal}: {row.Meat}")
Cattle[note 3] (list): beef veal Chicken (list): poultry Deer: venison humble (organ meat) DogfishAlso see Shark: Spiny dogfish capeshark (USA) flake (UK, AUS) huss (UK) kahada (CAN)[50] rigg (UK)rock salmon (UK) Duck (list) Also see Mallard: poultry Elk (wapiti): venison Gaur: garabeef Goat (list): chevon cabrito mutton Goose: poultry Guinea fowl: poultry Guinea pig: cuy MallardAlso see Duck: poultry Moose: venison Peafowl: poultry Pig (list) Also see Boar: pork ham bacon Pigeon (list): squab RamAlso see Sheep: lamb mutton Red deer: venison Shark: flake (AUS) Sheep (list) Also see Ram: lamb mutton hogget Snail: escargot Turkey (list): poultry Water buffalo: carabeef Whale: blubber
So now there's another problem - there are footnotes and links that makes things a bit messy. We could just clear out all link references in the HTML but that would destroy the animal names which are themselves links so I'll just do some string substitution in pandas instead to erase them.
FOOTNOTES = r"\[\w*\s*\d\]"
FOOTNOTES_2 = r"\s" + FOOTNOTES
EMPTY = ""
SPACE = " "
LIST = r"\(list\)"
for column in table.columns:
table[column] = table[column].str.replace(FOOTNOTES_2, EMPTY)
table[column] = table[column].str.replace(FOOTNOTES, SPACE)
table[column] = table[column].str.replace(LIST, EMPTY)
print()
print(table.loc[32:32])
Animal Young Female Male Collective noun \
32 Cattle calf cow bull herd drove yoke (oxen) team (oxen)
Collateral adjective Culinary noun for meat
32 bovine taurine (male) vaccine (female) vituli... beef veal
meats = table.dropna(subset=["Culinary noun for meat"])
meats = meats.rename(columns={"Culinary noun for meat": "Meat"})
for row in meats.itertuples():
print(f"{row.Animal}: {row.Meat}")
Cattle : beef veal Chicken : poultry Deer: venison humble (organ meat) DogfishAlso see Shark: Spiny dogfish capeshark (USA) flake (UK, AUS) huss (UK) kahada (CAN) rigg (UK)rock salmon (UK) Duck Also see Mallard: poultry Elk (wapiti): venison Gaur: garabeef Goat : chevon cabrito mutton Goose: poultry Guinea fowl: poultry Guinea pig: cuy MallardAlso see Duck: poultry Moose: venison Peafowl: poultry Pig Also see Boar: pork ham bacon Pigeon : squab RamAlso see Sheep: lamb mutton Red deer: venison Shark: flake (AUS) Sheep Also see Ram: lamb mutton hogget Snail: escargot Turkey : poultry Water buffalo: carabeef Whale: blubber
And now we have another prolbem - there's a weird smashing together of words (e.g. DogfishAlso) which appears to happen because wikipedia inserts <br/> tags to create a sub-row within the table rows and pandas appears to smash the rows together. Time to try again - I'm going to reload the soup and add a replace call to get rid of the breaks.
soup = BeautifulSoup(browser.page_source)
soup_table = soup.find_all("table")[-1]
for character in ascii_uppercase:
element = soup_table.find(id=character)
if element is None:
print(f"Element for {character} not found")
else:
element.parent.parent.decompose()
for tag in soup_table.find_all("br"):
tag.replace_with(SPACE)
soup_table.smooth()
soup_table.encode()
table = pandas.read_html(str(soup_table))[0]
print(TABLE(table[table.Animal.str.startswith("Ram")]))
| Animal | Young | Female | Male | Collective noun | Collateral adjective | Culinary noun for meat |
|---|---|---|---|---|---|---|
| Ram Also see Sheep | lamb | ewe | ram | flock | arietine ovine | lamb mutton |
So that fixes the smashing together, time to get rid of the footnotes and links to lists.
print(table.loc[32:32])
for column in table.columns:
table[column] = table[column].str.replace(FOOTNOTES_2, EMPTY)
table[column] = table[column].str.replace(FOOTNOTES, SPACE)
table[column] = table[column].str.replace(LIST, EMPTY)
print()
print(table.loc[32:32])
Animal Young Female Male \
32 Cattle[note 3] (list) calf[31] cow[32] bull
Collective noun \
32 herd[11] drove[11] yoke (oxen) team (oxen)
Collateral adjective Culinary noun for meat
32 bovine[note 4] taurine (male) vaccine (female)... beef veal
Animal Young Female Male Collective noun \
32 Cattle calf cow bull herd drove yoke (oxen) team (oxen)
Collateral adjective Culinary noun for meat
32 bovine taurine (male) vaccine (female) vituli... beef veal
And once again, the meats.
meats = table.dropna(subset=["Culinary noun for meat"])
meats = meats.rename(columns={"Culinary noun for meat": "Meat"})
for row in meats.itertuples():
print(f"{row.Animal}: {row.Meat}")
Cattle : beef veal Chicken : poultry Deer: venison humble (organ meat) Dogfish Also see Shark: Spiny dogfish capeshark (USA) flake (UK, AUS) huss (UK) kahada (CAN) rigg (UK) rock salmon (UK) Duck Also see Mallard: poultry Elk (wapiti): venison Gaur: garabeef Goat : chevon cabrito mutton Goose: poultry Guinea fowl: poultry Guinea pig: cuy Mallard Also see Duck: poultry Moose: venison Peafowl: poultry Pig Also see Boar: pork ham bacon Pigeon : squab Ram Also see Sheep: lamb mutton Red deer: venison Shark: flake (AUS) Sheep Also see Ram: lamb mutton hogget Snail: escargot Turkey : poultry Water buffalo: carabeef Whale: blubber
This isn't quite the nice set that I was hoping for, but, oh well. Maybe just one more clean-up to put paretheses around the Also see statements and onward.
PATTERN = "Also see (?P<name>\w+)"
def see_also(match):
name = match["name"]
return f"(Also see {name})"
table["Animal"] = table.Animal.str.replace(PATTERN, see_also)
for column in table.columns:
table[column] = table[column].str.strip()
meats = table.dropna(subset=["Culinary noun for meat"])
meats = meats.rename(columns={"Culinary noun for meat": "Meat"})
for row in meats.itertuples():
print(f"{row.Animal}: {row.Meat}")
Cattle: beef veal Chicken: poultry Deer: venison humble (organ meat) Dogfish (Also see Shark): Spiny dogfish capeshark (USA) flake (UK, AUS) huss (UK) kahada (CAN) rigg (UK) rock salmon (UK) Duck (Also see Mallard): poultry Elk (wapiti): venison Gaur: garabeef Goat: chevon cabrito mutton Goose: poultry Guinea fowl: poultry Guinea pig: cuy Mallard (Also see Duck): poultry Moose: venison Peafowl: poultry Pig (Also see Boar): pork ham bacon Pigeon: squab Ram (Also see Sheep): lamb mutton Red deer: venison Shark: flake (AUS) Sheep (Also see Ram): lamb mutton hogget Snail: escargot Turkey: poultry Water buffalo: carabeef Whale: blubber
And now to save it for later.
load_dotenv()
path = Path(os.environ["WIKIPEDIA"]).expanduser()
if not path.is_dir():
path.mkdir()
path = Path(os.environ["WIKIPEDIA_ANIMALS"])
table.to_csv(path, index=False)
And for an example use.
animals = pandas.read_csv(
Path(os.environ["WIKIPEDIA_ANIMALS"]).expanduser())
print(animals.sample(1).iloc[0])
Animal Marmoset Young infant Female ? Male ? Collective noun ? Collateral adjective simian Culinary noun for meat NaN Name: 155, dtype: object
print(meats.sample(1).iloc[0])
Animal Dogfish (Also see Shark) Young ? Female ? Male ? Collective noun troop Collateral adjective selachian squaloid Meat Spiny dogfish capeshark (USA) flake (UK, AUS) ... Name: 59, dtype: object
So, there we go. What have we learned?
Not so exciting, but it took longer than I thought it would. I blame the dog-days of August - the heat, it drives one mental.