MNIST Multi-Layer Perceptron with Validation
Table of Contents
Introduction
This is from Udacity's Deep Learning Repository which supports their Deep Learning Nanodegree.
We are going to train a Multi-Layer Perceptron to classify images from the MNIST database of hand-written digits.
Setup
Imports
From Python
from datetime import datetime
from typing import Tuple
import gc
From PyPi
from dotenv import load_dotenv
from sklearn.model_selection import train_test_split
from torchvision import datasets
import matplotlib.pyplot as pyplot
import seaborn
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torch
import numpy
This Project
from neurotic.tangles.data_paths import DataPathTwo
Setup the Plotting
get_ipython().run_line_magic('matplotlib', 'inline')
seaborn.set(style="whitegrid",
rc={"axes.grid": False,
"font.family": ["sans-serif"],
"font.sans-serif": ["Latin Modern Sans", "Lato"],
"figure.figsize": (14, 12)},
font_scale=3)
Types
Outcome = Tuple[float]
The Data
The Path To the Data
load_dotenv()
path = DataPathTwo(folder_key="MNIST")
print(path.folder)
assert path.folder.exists()
/home/hades/datasets/MNIST
Some Settings
Since I downloaded the data earlier for some other exercise forking sub-processes is probably unnecessary, and for the training and testing we'll use a relatively small batch-size of 20.
WORKERS = 0
BATCH_SIZE = 20
VALIDATION_PROPORTION = 0.2
LEARNING_RATE = 0.01
A Transform
We're just going to convert the images to tensors.
transform = transforms.ToTensor()
Split Up the Training and Testing Data
training_data = datasets.MNIST(root=path.folder, train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root=path.folder, train=False,
download=True, transform=transform)
Make a Validation Set
Now we're going to re-split the training-data into training and validation data. First we're going to generate indices for each set using sklearn's train_test_split.
indices = list(range(len(training_data)))
training_indices, validation_indices = train_test_split(indices, test_size=VALIDATION_PROPORTION)
print(len(training_indices))
print(len(validation_indices))
assert len(validation_indices)/len(indices) == VALIDATION_PROPORTION
48000 12000
Now that we have our indices we need to create some samplers that can be passed to the Data Loaders. We need them to create the batches from our data.
training_sampler = torch.utils.data.SubsetRandomSampler(training_indices)
validation_sampler = torch.utils.data.SubsetRandomSampler(validation_indices)
Create The Data Loaders
Now we will create the batch-iterators.
training_batches = torch.utils.data.DataLoader(
training_data, batch_size=BATCH_SIZE, sampler=training_sampler,
num_workers=WORKERS)
For the validation batch we pass in the training data and use the validation-sampler to create a separate set of batches.
validation_batches = torch.utils.data.DataLoader(
training_data, batch_size=BATCH_SIZE, sampler=validation_sampler,
num_workers=WORKERS)
Since we're not splitting the testing data it doesn't get a sampler.
test_batches = torch.utils.data.DataLoader(
test_data, batch_size=BATCH_SIZE,
num_workers=WORKERS)
Visualize a Batch of Training Data
Our first step is to take a look at the data, make sure it is loaded in correctly, then make any initial observations about patterns in that data.
Grab a batch
images, labels = iter(training_batches).next()
images = images.numpy()
Now that we have a batch we're going to plot the images in the batch, along with the corresponding labels.
seaborn.set(font_scale=1.5)
figure = pyplot.figure(figsize=(25, 4))
figure.suptitle("First Batch", weight="bold", y=1.2)
for index in numpy.arange(BATCH_SIZE):
ax = figure.add_subplot(2, BATCH_SIZE/2, index+1, xticks=[], yticks=[])
ax.imshow(numpy.squeeze(images[index]), cmap='gray')
# print out the correct label for each image
# .item() gets the value contained in a Tensor
ax.set_title(str(labels[index].item()))
View a Single Image
Now we're going to take a closer look at the second image in the batch.
image = numpy.squeeze(images[1])
seaborn.set(font_scale=1, style="white")
figure = pyplot.figure(figsize = (12,12))
figure.suptitle(str(labels[1].item()), fontsize="xx-large", weight="bold")
ax = figure.add_subplot(111)
ax.imshow(image, cmap='gray')
width, height = image.shape
threshold = image.max()/2.5
for x in range(width):
for y in range(height):
val = round(image[x][y],2) if image[x][y] !=0 else 0
ax.annotate(str(val), xy=(y,x),
horizontalalignment='center',
verticalalignment='center',
color='white' if image[x][y]<threshold else 'black')

We're looking at a single image with the normalized values for each pixel superimposed on it. It looks like black is 0 and white is 1, although for this image most of the 'white' pixels are just a little less than one.
Define the Network Architecture
The architecture will be responsible for seeing as input a 784-dim Tensor of pixel values for each image, and producing a Tensor of length 10 (our number of classes) that indicates the class scores for an input image. This particular example uses two hidden layers and dropout to avoid overfitting.
These values are based on the keras example implementation.
INPUT_NODES = 28 * 28
HIDDEN_NODES_1 = HIDDEN_NODES_2 = 512
DROPOUT = 0.2
CLASSES = 10
class MultiLayerPerceptron(nn.Module):
"""A Multi-Layer Perceptron
This is a network with 2 hidden layers
"""
def __init__(self):
super().__init__()
self.fully_connected_layer_1 = nn.Linear(INPUT_NODES, HIDDEN_NODES_1)
self.fully_connected_layer_2 = nn.Linear(HIDDEN_NODES_1, HIDDEN_NODES_2)
self.output = nn.Linear(HIDDEN_NODES_2, CLASSES)
self.dropout = nn.Dropout(p=DROPOUT)
return
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""One feed-forward through the network
Args:
x: a 28 x 28 tensor
Returns:
tensor: output of the network without activation
"""
# flatten image input
x = x.view(-1, INPUT_NODES)
x = self.dropout(F.relu(self.fully_connected_layer_1(x)))
x = self.dropout(F.relu(self.fully_connected_layer_2(x)))
return self.output(x)
Initialize the Neural Network
model = MultiLayerPerceptron()
print(model)
MultiLayerPerceptron( (fully_connected_layer_1): Linear(in_features=784, out_features=512, bias=True) (fully_connected_layer_2): Linear(in_features=512, out_features=512, bias=True) (output): Linear(in_features=512, out_features=10, bias=True) (dropout): Dropout(p=0.2) )
A Little CUDA
This sets it up to use CUDA (if available).
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
if torch.cuda.device_count() > 1:
print("Using {} GPUs".format(torch.cuda.device_count()))
model = nn.DataParallel(model)
model.to(device)
else:
print("Only 1 GPU available")
Only 1 GPU available
Specify the Loss Function and Optimizer
We're going to use cross-entropy loss for classification. PyTorch's cross entropy function applies a softmax function to the output layer and then calculates the log loss (so you don't want to do softmax as part of the model output).
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE)
Train the Network
We're going to do a quasi-search by optimizing over 50 epochs and keeping the model that has the best validation score.
# number of epochs to train the model
EPOCHS = 50
SAVED_MODEL= 'multilayer_perceptron.pt'
def process_batch(model: nn.Module, data: torch.Tensor, target: torch.Tensor,
device: str) -> Outcome:
"""process one batch of the data
Args:
model: model to predict target
data: data to use to predict target
target: what we're trying to predict
device: cpu or gpu
Returns:
outcome: loss and correct count
"""
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
_, predicted = torch.max(output.data, 1)
return loss, (predicted == target).sum().item()
def train(model: nn.Module,
batches: torch.utils.data.DataLoader,
device: str,
) -> Outcome:
"""Perform one forward pass through the batches
Args:
model: thing to train
batches: batch-iterator of training data
device: cpu or cuda device
Returns:
outcome: cumulative loss, accuracy for the batches
"""
total_loss = 0.0
count = 0
total_correct = 0
model.train()
for data, target in batches:
optimizer.zero_grad()
loss, correct = process_batch(model, data, target, device)
count += target.size(0)
total_correct += correct
total_loss += loss
loss.backward()
optimizer.step()
total_loss += loss.item() * data.size(0)
return total_loss, total_correct/count
def validate(model: nn.Module, batches: torch.utils.data.DataLoader,
device: str) -> Outcome:
"""Calculate the loss for the model
Args:
model: the model to validate
batches: the batch-iterator of validation data
device: cuda or cpu
Returns:
Outcome: Cumulative loss, Accuracy over batches
"""
model.eval()
total_loss = 0.0
total_correct = 0
count = 0
for data, target in batches:
loss, correct = process_batch(model, data, target, device)
count += target.size(0)
total_correct += correct
total_loss += loss.item() * data.size(0)
return total_loss, total_correct/count
# initialize tracker for minimum validation loss
lowest_validation_loss = numpy.Inf
training_losses = []
validation_losses = []
training_accuracies = []
validation_accuracies = []
for epoch in range(1, EPOCHS + 1):
loss, accuracy = train(model, training_batches, device)
training_losses.append(loss)
mean_training_loss = loss/len(training_batches.dataset)
training_accuracies.append(accuracy)
loss, accuracy = validate(model, validation_batches, device)
validation_losses.append(loss)
mean_validation_loss = loss/len(validation_batches.dataset)
validation_accuracies.append(accuracy)
if mean_validation_loss <= lowest_validation_loss:
print('Epoch {}: Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
epoch,
lowest_validation_loss,
mean_validation_loss))
torch.save(model.state_dict(), SAVED_MODEL)
lowest_validation_loss = mean_validation_loss
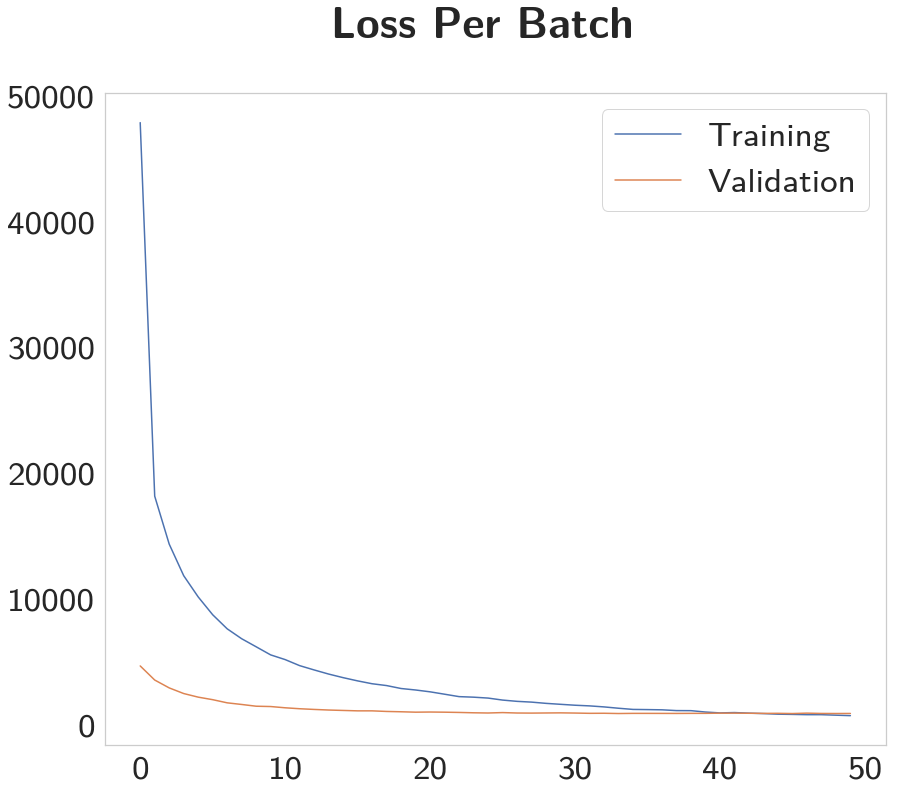
Epoch 1: Validation loss decreased (inf --> 0.076556). Saving model ... Epoch 2: Validation loss decreased (0.076556 --> 0.058478). Saving model ... Epoch 3: Validation loss decreased (0.058478 --> 0.049405). Saving model ... Epoch 4: Validation loss decreased (0.049405 --> 0.043155). Saving model ... Epoch 5: Validation loss decreased (0.043155 --> 0.037079). Saving model ... Epoch 6: Validation loss decreased (0.037079 --> 0.032932). Saving model ... Epoch 7: Validation loss decreased (0.032932 --> 0.029682). Saving model ... Epoch 8: Validation loss decreased (0.029682 --> 0.028046). Saving model ... Epoch 9: Validation loss decreased (0.028046 --> 0.025318). Saving model ... Epoch 10: Validation loss decreased (0.025318 --> 0.023867). Saving model ... Epoch 11: Validation loss decreased (0.023867 --> 0.022447). Saving model ... Epoch 12: Validation loss decreased (0.022447 --> 0.021411). Saving model ... Epoch 13: Validation loss decreased (0.021411 --> 0.020793). Saving model ... Epoch 14: Validation loss decreased (0.020793 --> 0.019830). Saving model ... Epoch 15: Validation loss decreased (0.019830 --> 0.018676). Saving model ... Epoch 16: Validation loss decreased (0.018676 --> 0.018644). Saving model ... Epoch 17: Validation loss decreased (0.018644 --> 0.017666). Saving model ... Epoch 18: Validation loss decreased (0.017666 --> 0.017635). Saving model ... Epoch 20: Validation loss decreased (0.017635 --> 0.016688). Saving model ... Epoch 21: Validation loss decreased (0.016688 --> 0.016489). Saving model ... Epoch 22: Validation loss decreased (0.016489 --> 0.016364). Saving model ... Epoch 23: Validation loss decreased (0.016364 --> 0.015944). Saving model ... Epoch 24: Validation loss decreased (0.015944 --> 0.015633). Saving model ... Epoch 26: Validation loss decreased (0.015633 --> 0.015446). Saving model ... Epoch 27: Validation loss decreased (0.015446 --> 0.015257). Saving model ... Epoch 30: Validation loss decreased (0.015257 --> 0.015216). Saving model ... Epoch 31: Validation loss decreased (0.015216 --> 0.015175). Saving model ... Epoch 34: Validation loss decreased (0.015175 --> 0.014866). Saving model ... Epoch 36: Validation loss decreased (0.014866 --> 0.014530). Saving model ...
The training and validation loss seems surprisingly good.
x = list(range(len(training_losses)))
figure, axe = pyplot.subplots()
figure.suptitle("Loss Per Batch", weight="bold")
axe.plot(x, training_losses, label="Training")
axe.plot(x, validation_losses, label="Validation")
legend = axe.legend()
So it looks like it improves fairly quickly then after 36 epochs the model stops improving.
Testing the Best Model
model.load_state_dict(torch.load(SAVED_MODEL))
test_loss = 0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval()
for data, target in test_batches:
output = model(data)
data, target = data.to(device), target.to(device)
# calculate the loss
loss = criterion(output, target)
# update test loss
test_loss += loss.item()*data.size(0)
# convert output probabilities to predicted class
_, pred = torch.max(output, 1)
# compare predictions to true label
correct = numpy.squeeze(pred.eq(target.data.view_as(pred)))
# calculate test accuracy for each object class
for i in range(BATCH_SIZE):
label = target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# calculate and print avg test loss
test_loss = test_loss/len(test_batches.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for i in range(10):
if class_total[i] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
str(i), 100 * class_correct[i] / class_total[i],
numpy.sum(class_correct[i]), numpy.sum(class_total[i])))
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
Test Loss: 0.059497 Test Accuracy of 0: 99% (974/980) Test Accuracy of 1: 99% (1127/1135) Test Accuracy of 2: 97% (1009/1032) Test Accuracy of 3: 98% (994/1010) Test Accuracy of 4: 97% (960/982) Test Accuracy of 5: 97% (867/892) Test Accuracy of 6: 98% (941/958) Test Accuracy of 7: 98% (1008/1028) Test Accuracy of 8: 97% (947/974) Test Accuracy of 9: 97% (986/1009)
Visualize Test Results
images, labels = iter(test_batches).next()
# matplotlib doesn't like the CUDA and the model doesn't like the CPU... too bad for the model.
model.to("cpu")
output = model(images)
_, preds = torch.max(output, 1)
# prep images for display
images = images.numpy()
# plot the images in the batch, along with predicted and true labels
figure = pyplot.figure(figsize=(25, 4))
title = figure.suptitle("Test Predictions", weight="bold", position=(0.5, 1.3))
for index in numpy.arange(20):
ax = figure.add_subplot(2, 20/2, index+1, xticks=[], yticks=[])
ax.imshow(numpy.squeeze(images[index]), cmap='gray')
ax.set_title("{} ({})".format(str(preds[index].item()), str(labels[index].item())),
color=("green" if preds[index]==labels[index] else "red"))
figure.tight_layout()

Object-Oriented Trainer
This just bundles up the earlier stuff.
class Trainer:
"""Train-test-validate the model
Args:
train: training batches
validate: validation batches
test: testing batches
epochs: number of times to repeat training over the batches
model_filename: name to save the hyperparameters of best model
learning_rate: how much to update the weights
"""
def __init__(self, train: torch.utils.data.DataLoader,
validate: torch.utils.data.DataLoader,
test: torch.utils.data.DataLoader,
epochs: int=50,
model_filename: str="multilayer_perceptron.pth",
learning_rate=0.01) -> None:
self.training_batches = train
self.validation_batches = validate
self.test_batches = test
self.epochs = epochs
self.save_as = model_filename
self.learning_rate = learning_rate
self._model = None
self._criterion = None
self._optimizer = None
self._device = None
self.validation_losses = []
self.training_losses = []
self.validation_accuracies = []
self.training_accuracies = []
self.best_parameters = None
return
@property
def model(self):
"""The Multi-Layer Perceptron"""
if self._model is None:
self._model = model = MultiLayerPerceptron()
self._model.to(self.device)
return self._model
@property
def criterion(self):
"""The Loss Measurer"""
if self._criterion is None:
self._criterion = nn.CrossEntropyLoss()
return self._criterion
@property
def optimizer(self):
"""The gradient descent"""
if self._optimizer is None:
self._optimizer = torch.optim.SGD(self.model.parameters(),
lr=self.learning_rate)
return self._optimizer
@property
def device(self):
"""The CPU or GPU"""
if self._device is None:
self._device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
return self._device
def process_batch(self, data: torch.Tensor, target: torch.Tensor) -> Outcome:
"""process one batch of the data
Args:
data: data to use to predict target
target: what we're trying to predict
device: cpu or gpu
Returns:
outcome: loss and correct count
"""
data, target = data.to(self.device), target.to(self.device)
output = self.model(data)
loss = self.criterion(output, target)
_, predicted = torch.max(output.data, 1)
return loss, (predicted == target).sum().item()
def train(self) -> Outcome:
"""Perform one forward pass through the batches
Returns:
outcome: cumulative loss, accuracy for the batches
"""
total_loss = 0.0
count = 0
total_correct = 0
self.model.train()
for data, target in self.training_batches:
self.optimizer.zero_grad()
loss, correct = self.process_batch(data, target)
count += target.size(0)
total_correct += correct
total_loss += loss
loss.backward()
self.optimizer.step()
total_loss += loss.item() * data.size(0)
del loss
return float(total_loss), float(total_correct/count)
def validate(self) -> Outcome:
"""Calculate the loss for the model
Returns:
Outcome: Cumulative loss, Accuracy over batches
"""
self.model.eval()
total_loss = 0.0
total_correct = 0
count = 0
for data, target in self.validation_batches:
loss, correct = self.process_batch(data, target)
count += target.size(0)
total_correct += correct
total_loss += loss.item() * data.size(0)
del loss
return float(total_loss), float(total_correct/count)
def run_training(self) -> None:
"""Runs the training and validation"""
lowest_validation_loss = numpy.Inf
for epoch in range(1, self.epochs + 1):
gc.collect()
loss, accuracy = self.train()
self.training_losses.append(loss)
mean_training_loss = loss/len(self.training_batches.dataset)
self.training_accuracies.append(accuracy)
loss, accuracy = self.validate()
self.validation_losses.append(loss)
mean_validation_loss = loss/len(self.validation_batches.dataset)
self.validation_accuracies.append(accuracy)
if mean_validation_loss <= lowest_validation_loss:
print('Epoch {}: Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
epoch,
lowest_validation_loss,
mean_validation_loss))
self.best_parameters = self.model.state_dict()
torch.save(self.best_parameters, self.save_as)
lowest_validation_loss = mean_validation_loss
return
def test(self):
"""Test Our Model"""
if self.best_parameters is None:
raise Exception("call ``run_training`` or set ``best_parameters")
self.model.load_state_dict(self.best_parameters)
test_loss = 0.0
digits = 10
class_correct = [0.0] * digits
class_total = [0.0] * digits
self.model.eval()
for data, target in self.test_batches:
output = self.model(data)
data, target = data.to(device), target.to(device)
loss = self.criterion(output, target)
test_loss += loss.item() * data.size(0)
_, predictions = torch.max(output, 1)
correct = numpy.squeeze(predictions.eq(
target.data.view_as(predictions)))
# calculate test accuracy for each object class
for i in range(data.size(0)):
label = target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# calculate and print avg test loss
test_loss = test_loss/len(self.test_batches.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for digit in range(10):
if class_total[digit] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
str(digit), 100 * class_correct[digit] / class_total[digit],
numpy.sum(class_correct[digit]), numpy.sum(class_total[digit])))
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[digit]))
return
For some reason, this raises an error when the backward propagation step is run.
RuntimeError: CUDA error: out of memory
So I can't run it until I figure out what's going on. Update - it looks like casting the outputs of the functions to floats solved the problem. Apparently even they look like floats, whatever the item() method returns prevents the freeing up of the memory, so casting them to floats fixes the memory problem.
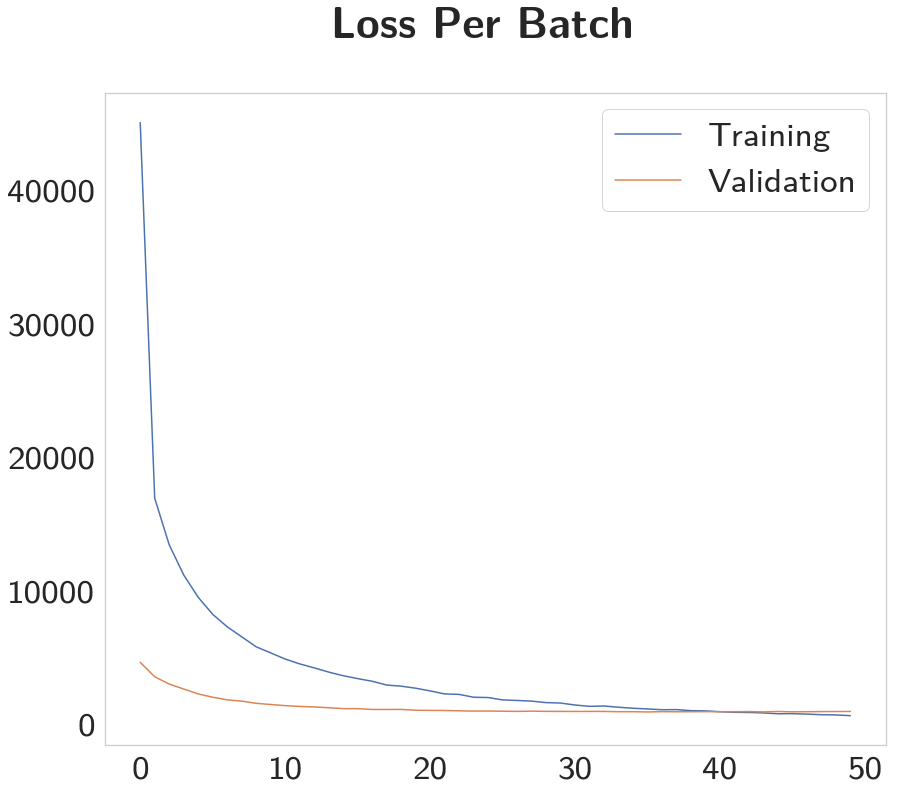
trainer = Trainer(training_batches, validation_batches, test_batches)
trainer.run_training()
Epoch 1: Validation loss decreased (inf --> 0.077417). Saving model ... Epoch 2: Validation loss decreased (0.077417 --> 0.058746). Saving model ... Epoch 3: Validation loss decreased (0.058746 --> 0.048325). Saving model ... Epoch 4: Validation loss decreased (0.048325 --> 0.040851). Saving model ... Epoch 5: Validation loss decreased (0.040851 --> 0.036083). Saving model ... Epoch 6: Validation loss decreased (0.036083 --> 0.032722). Saving model ... Epoch 7: Validation loss decreased (0.032722 --> 0.028545). Saving model ... Epoch 8: Validation loss decreased (0.028545 --> 0.026376). Saving model ... Epoch 9: Validation loss decreased (0.026376 --> 0.024063). Saving model ... Epoch 10: Validation loss decreased (0.024063 --> 0.023637). Saving model ... Epoch 11: Validation loss decreased (0.023637 --> 0.021980). Saving model ... Epoch 12: Validation loss decreased (0.021980 --> 0.020723). Saving model ... Epoch 13: Validation loss decreased (0.020723 --> 0.019802). Saving model ... Epoch 14: Validation loss decreased (0.019802 --> 0.019013). Saving model ... Epoch 15: Validation loss decreased (0.019013 --> 0.018458). Saving model ... Epoch 16: Validation loss decreased (0.018458 --> 0.017919). Saving model ... Epoch 17: Validation loss decreased (0.017919 --> 0.017918). Saving model ... Epoch 18: Validation loss decreased (0.017918 --> 0.017127). Saving model ... Epoch 19: Validation loss decreased (0.017127 --> 0.016704). Saving model ... Epoch 20: Validation loss decreased (0.016704 --> 0.016167). Saving model ... Epoch 22: Validation loss decreased (0.016167 --> 0.016154). Saving model ... Epoch 23: Validation loss decreased (0.016154 --> 0.015817). Saving model ... Epoch 24: Validation loss decreased (0.015817 --> 0.015352). Saving model ... Epoch 25: Validation loss decreased (0.015352 --> 0.015075). Saving model ... Epoch 27: Validation loss decreased (0.015075 --> 0.015059). Saving model ... Epoch 28: Validation loss decreased (0.015059 --> 0.014940). Saving model ... Epoch 32: Validation loss decreased (0.014940 --> 0.014644). Saving model ... Epoch 34: Validation loss decreased (0.014644 --> 0.014383). Saving model ... Epoch 46: Validation loss decreased (0.014383 --> 0.014357). Saving model ...
x = list(range(len(trainer.training_accuracies)))
figure, axe = pyplot.subplots()
figure.suptitle("Model Accuracy", weight="bold")
axe.plot(x, trainer.training_accuracies, label="Training")
axe.plot(x, trainer.validation_accuracies, label="Validation")
legend = axe.legend()
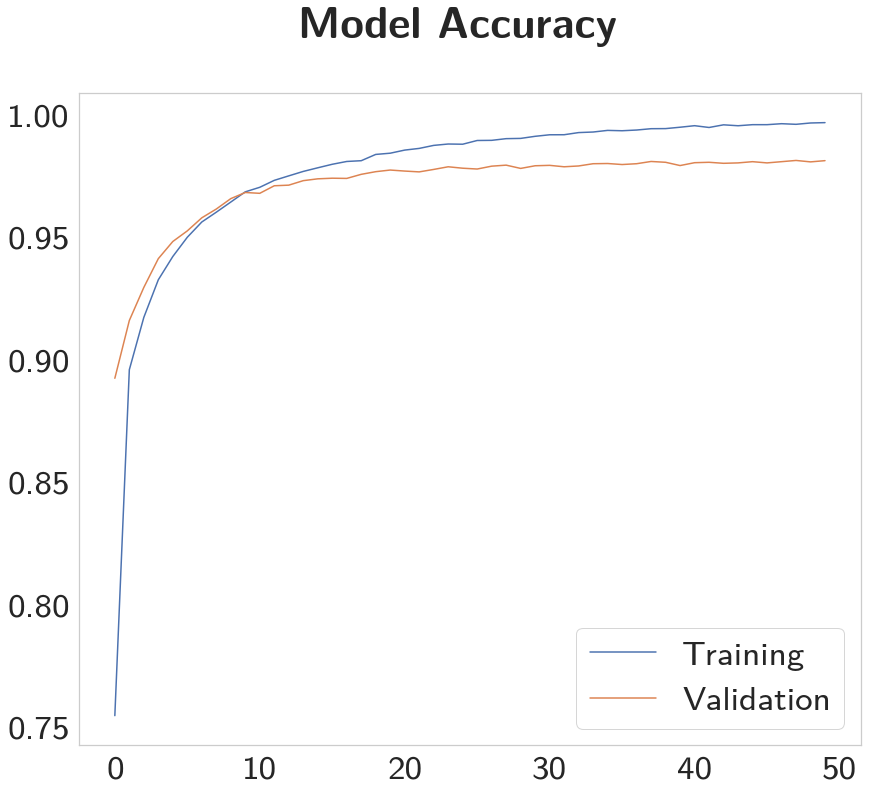
Although the validation loss decreases for a while, it nearly reaches its peak accuracy around 10 epochs. The training worked out a little differently this time, so here's the losses again.
x = list(range(len(trainer.training_losses)))
figure, axe = pyplot.subplots()
figure.suptitle("Loss Per Batch", weight="bold")
axe.plot(x, trainer.training_losses, label="Training")
axe.plot(x, trainer.validation_losses, label="Validation")
legend = axe.legend()