Further Noise Reduction
Table of Contents
Set Up
Debug
%load_ext autoreload
%autoreload 2
Imports
Python Standard Library
from collections import Counter
from functools import partial
import pickle
PyPi
from tabulate import tabulate
import matplotlib.pyplot as pyplot
import seaborn
This Project
from neurotic.tangles.data_paths import DataPath
Tables
table = partial(tabulate, tablefmt="orgtbl", headers="keys")
Plotting
%matplotlib inline
seaborn.set_style("whitegrid")
FIGURE_SIZE = (12, 10)
Helpers
def print_most_common(counter: Counter, count: int=10, bottom=False) -> None:
"""Prints most common tokens as an org-tabel"""
tokens, counts = [], []
for token, count in sorted(counter.items(), reverse=bottom)[:count]:
tokens.append(token)
counts.append(count)
print(table(dict(Token=tokens, Count=counts)))
return
Further Noise Reduction
Speeding up our network by only using relevant nodes was a useful thing insofar as it lets us train bigger datasets without having to wait infeasible amounts of time, but it doesn't directly address the problem we saw earlier, which is that many of our nodes don't actually contribute to the classification.
Here's the words that are most commonly positive.
with DataPath("pos_neg_ratios.pkl").from_folder.open("rb") as writer:
pos_neg_ratios = pickle.load(writer)
print_most_common(pos_neg_ratios)
| Token | Count |
|---|---|
| 0.976102 | |
| . | 0.952936 |
| a | 1.05504 |
| aa | 0.5 |
| aaa | 0.428571 |
| aaaaaaah | 0 |
| aaaaah | 0 |
| aaaaatch | 1 |
| aaaahhhhhhh | 0 |
| aaaand | 1 |
It's difficult to imagine that these are really telling us how to discern a positive review, since they are mostly names, not descriptive adjectives, nouns, or the like.
Here's the most common negative words.
print_most_common(pos_neg_ratios, bottom=True)
| Token | Count |
|---|---|
| zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz | 0 |
| zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz | 0 |
| zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz | 0 |
| zzzzzzzzzzzzz | 0 |
| zzzzzzzzzzzz | 0 |
| zzzzzzzz | 0 |
| zzzzz | 0 |
| zzzz | 0 |
| zz | 0 |
| zyuranger | 0 |
frequency_frequency = Counter()
for word, cnt in total_counts.most_common():
frequency_frequency[cnt] += 1
figure, axe = pyplot.subplots(figsize=FIGURE_SIZE)
plot = seaborn.distplot(list(map(lambda x: x[1], frequency_frequency.most_common())))
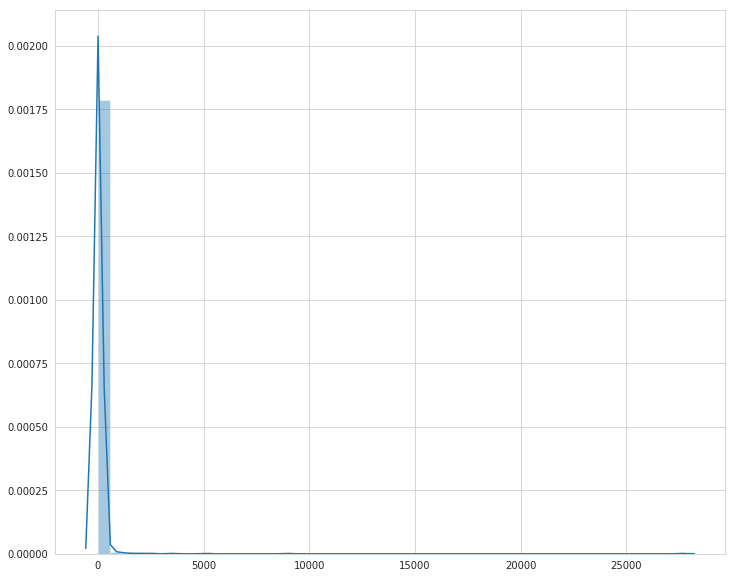
As we can see from the plot, there are a small number of terms that make up a significant amount of the tokens, and a significant amount of the terms that don't really contribute to the outcome.
Reducing Noise by Strategically Reducing the Vocabulary
We're going to try and improve the network by not including tokens that are too rare or don't contribute enough to the sentiments.
# python standard library
from typing import List
from collections import Counter
# from pypi
import numpy
# this project
from sentimental_network import SentiMental
The Sentiment Noise Reduction Network
This is going to be kind of another overhaul of our network. We're going to build off of our previous Sentiment Network that only did calculations on tokens per review, not on the entire vocabulary.
class SentimentNoiseReduction(SentiMental):
"""reduces noise
... uml::
SentimentNoiseReduction --|> SentiMental
Args:
lower_bound: threshold to add token to network
polarity_cutoff: threshold for positive-negative ratio for words
"""
def __init__(self, polarity_cutoff, lower_bound: int=50, *args, **kwargs):
super().__init__(*args, **kwargs)
self.lower_bound = lower_bound
self.polarity_cutoff = polarity_cutoff
self._positive_counts = None
self._negative_counts = None
self._total_counts = None
self._positive_negative_ratios = None
return
The Review Vocabulary
Our first change is that we'll only add words to the vocabulary that meet certain thresholds. Unfortunately the way the attributes are currently set up, this needs the counts to be set up so it has the side effect of calling the count_tokens method.
@property
def review_vocabulary(self) -> List:
"""list of tokens in the reviews"""
if self._review_vocabulary is None:
# this needs to be called before total counts is used
self.count_tokens()
vocabulary = set()
for review in self.reviews:
tokens = set(review.split(self.tokenizer))
tokens = (token for token in tokens
if self.total_counts[token] > self.lower_bound)
tokens = (
token for token in tokens
if abs(self.positive_negative_ratios[token])
>= self.polarity_cutoff)
vocabulary.update(tokens)
self._review_vocabulary = list(vocabulary)
return self._review_vocabulary
Positive Counts
This is actually a building-block for our positive-to-negative ratios. It just holds the counts of the tokens in the positive reviews.
@property
def positive_counts(self) -> Counter:
"""Token counts for positive reviews"""
if self._positive_counts is None:
self._positive_counts = Counter()
return self._positive_counts
Negative Counts
Like the negative counts, this is the count of tokens in the negative reviews.
@property
def negative_counts(self) -> Counter:
"""Token counts for negative reviews"""
if self._negative_counts is None:
self._negative_counts = Counter()
return self._negative_counts
Total Counts
Once again related to the outher counts, this holds the counts for all tokens, regardless of their sentiment.
@property
def total_counts(self) -> Counter:
"""Token counts for total reviews"""
if self._total_counts is None:
self._total_counts = Counter()
return self._total_counts
Positive to Negative Ratios
This holds the logarithms of the ratios of positive to negative sentiments for a given token.
@property
def positive_negative_ratios(self) -> Counter:
"""log-ratio of positive to negative reviews"""
if self._positive_negative_ratios is None:
positive_negative_ratios = Counter()
positive_negative_ratios.update(
{token:
self.positive_counts[token]
/(self.negative_counts[token] + 1)
for token in self.total_counts})
for token, ratio in positive_negative_ratios.items():
if ratio > 1:
positive_negative_ratios[token] = numpy.log(ratio)
else:
positive_negative_ratios[token] = -numpy.log(1/(ratio + 0.01))
self._positive_negative_ratios = Counter()
self._positive_negative_ratios.update(positive_negative_ratios)
return self._positive_negative_ratios
Count Tokens
This is a method to populate the token counters.
def count_tokens(self):
"""Populate the count-tokens"""
self.reset_counters()
for label, review in zip(self.labels, self.reviews):
tokens = review.split(self.tokenizer)
self.total_counts.update(tokens)
if label == "POSITIVE":
self.positive_counts.update(tokens)
else:
self.negative_counts.update(tokens)
return
Reset Counters
This sets all the counters back to none. It is called by the count_tokens method, but in practice shouldn't really be needed.
def reset_counters(self):
"""Set the counters back to none"""
self._positive_counts = None
self._negative_counts = None
self._total_counts = None
self._positive_negative_ratios = None
return
Train and Test The Network
with DataPath("x_train.pkl").from_folder.open("rb") as reader:
x_train = pickle.load(reader)
with DataPath("y_train.pkl").from_folder.open("rb") as reader:
y_train = pickle.load(reader)
from sentiment_noise_reduction import SentimentNoiseReduction
sentimental = SentimentNoiseReduction(lower_bound=20,
polarity_cutoff=0.05,
learning_rate=0.01,
verbose=True)
sentimental.train(x_train, y_train)
Progress: 0.00 % Speed(reviews/sec): 0.00 Error: [-0.5] #Correct: 1 #Trained: 1 Training Accuracy: 100.00 % Progress: 4.17 % Speed(reviews/sec): 111.11 Error: [-0.36634265] #Correct: 748 #Trained: 1001 Training Accuracy: 74.73 % Progress: 8.33 % Speed(reviews/sec): 200.00 Error: [-0.2621193] #Correct: 1549 #Trained: 2001 Training Accuracy: 77.41 % Progress: 12.50 % Speed(reviews/sec): 272.73 Error: [-0.39176697] #Correct: 2396 #Trained: 3001 Training Accuracy: 79.84 % Progress: 16.67 % Speed(reviews/sec): 333.33 Error: [-0.24778501] #Correct: 3211 #Trained: 4001 Training Accuracy: 80.25 % Progress: 20.83 % Speed(reviews/sec): 384.62 Error: [-0.16868621] #Correct: 4031 #Trained: 5001 Training Accuracy: 80.60 % Progress: 25.00 % Speed(reviews/sec): 428.57 Error: [-0.05009294] #Correct: 4857 #Trained: 6001 Training Accuracy: 80.94 % Progress: 29.17 % Speed(reviews/sec): 466.67 Error: [-0.04235332] #Correct: 5726 #Trained: 7001 Training Accuracy: 81.79 % Progress: 33.33 % Speed(reviews/sec): 500.00 Error: [-0.05128397] #Correct: 6583 #Trained: 8001 Training Accuracy: 82.28 % Progress: 37.50 % Speed(reviews/sec): 529.41 Error: [-0.09180182] #Correct: 7434 #Trained: 9001 Training Accuracy: 82.59 % Progress: 41.67 % Speed(reviews/sec): 555.56 Error: [-0.3652018] #Correct: 8307 #Trained: 10001 Training Accuracy: 83.06 % Progress: 45.83 % Speed(reviews/sec): 578.95 Error: [-0.21013078] #Correct: 9162 #Trained: 11001 Training Accuracy: 83.28 % Progress: 50.00 % Speed(reviews/sec): 600.00 Error: [-0.01534277] #Correct: 10021 #Trained: 12001 Training Accuracy: 83.50 % Progress: 54.17 % Speed(reviews/sec): 619.05 Error: [-0.25971145] #Correct: 10893 #Trained: 13001 Training Accuracy: 83.79 % Progress: 58.33 % Speed(reviews/sec): 636.36 Error: [-0.0084308] #Correct: 11754 #Trained: 14001 Training Accuracy: 83.95 % Progress: 62.50 % Speed(reviews/sec): 652.17 Error: [-0.46920695] #Correct: 12591 #Trained: 15001 Training Accuracy: 83.93 % Progress: 66.67 % Speed(reviews/sec): 666.67 Error: [-0.19061036] #Correct: 13441 #Trained: 16001 Training Accuracy: 84.00 % Progress: 70.83 % Speed(reviews/sec): 680.00 Error: [-0.22740865] #Correct: 14295 #Trained: 17001 Training Accuracy: 84.08 % Progress: 75.00 % Speed(reviews/sec): 692.31 Error: [-0.0372273] #Correct: 15171 #Trained: 18001 Training Accuracy: 84.28 % Progress: 79.17 % Speed(reviews/sec): 703.70 Error: [-0.99387849] #Correct: 16045 #Trained: 19001 Training Accuracy: 84.44 % Progress: 83.33 % Speed(reviews/sec): 714.29 Error: [-0.05559484] #Correct: 16930 #Trained: 20001 Training Accuracy: 84.65 % Progress: 87.50 % Speed(reviews/sec): 724.14 Error: [-0.35082069] #Correct: 17805 #Trained: 21001 Training Accuracy: 84.78 % Progress: 91.67 % Speed(reviews/sec): 733.33 Error: [-0.43847381] #Correct: 18693 #Trained: 22001 Training Accuracy: 84.96 % Progress: 95.83 % Speed(reviews/sec): 741.94 Error: [-0.1589986] #Correct: 19546 #Trained: 23001 Training Accuracy: 84.98 % Training Time: 0:00:32.760293
with DataPath("x_test.pkl").from_folder.open("rb") as reader:
x_test = pickle.load(reader)
with DataPath("y_test.pkl").from_folder.open("rb") as reader:
y_test = pickle.load(reader)
sentimental.test(x_test, y_test)
Progress: 0.00% Speed(reviews/sec): 0.00 #Correct: 1 #Tested: 1 Testing Accuracy: 100.00 % Progress: 10.00% Speed(reviews/sec): 0.00 #Correct: 92 #Tested: 101 Testing Accuracy: 91.09 % Progress: 20.00% Speed(reviews/sec): 0.00 #Correct: 176 #Tested: 201 Testing Accuracy: 87.56 % Progress: 30.00% Speed(reviews/sec): 0.00 #Correct: 266 #Tested: 301 Testing Accuracy: 88.37 % Progress: 40.00% Speed(reviews/sec): 0.00 #Correct: 353 #Tested: 401 Testing Accuracy: 88.03 % Progress: 50.00% Speed(reviews/sec): 0.00 #Correct: 443 #Tested: 501 Testing Accuracy: 88.42 % Progress: 60.00% Speed(reviews/sec): 0.00 #Correct: 531 #Tested: 601 Testing Accuracy: 88.35 % Progress: 70.00% Speed(reviews/sec): 0.00 #Correct: 605 #Tested: 701 Testing Accuracy: 86.31 % Progress: 80.00% Speed(reviews/sec): 0.00 #Correct: 683 #Tested: 801 Testing Accuracy: 85.27 % Progress: 90.00% Speed(reviews/sec): 0.00 #Correct: 770 #Tested: 901 Testing Accuracy: 85.46 %
Strangely it deson't seem to have sped up the time or improved the testing accuracy. Now a network with a higher polarity cutoff.
sentimental = SentimentNoiseReduction(lower_bound=20,
polarity_cutoff=0.8,
learning_rate=0.01,
verbose=True)
sentimental.train(x_train, y_train)
Progress: 0.00 % Speed(reviews/sec): 0.00 Error: [-0.5] #Correct: 1 #Trained: 1 Training Accuracy: 100.00 % Progress: 4.17 % Speed(reviews/sec): 125.00 Error: [-0.39461068] #Correct: 840 #Trained: 1001 Training Accuracy: 83.92 % Progress: 8.33 % Speed(reviews/sec): 250.00 Error: [-0.51977448] #Correct: 1659 #Trained: 2001 Training Accuracy: 82.91 % Progress: 12.50 % Speed(reviews/sec): 333.33 Error: [-0.58021736] #Correct: 2490 #Trained: 3001 Training Accuracy: 82.97 % Progress: 16.67 % Speed(reviews/sec): 444.44 Error: [-0.48964892] #Correct: 3300 #Trained: 4001 Training Accuracy: 82.48 % Progress: 20.83 % Speed(reviews/sec): 555.56 Error: [-0.41779146] #Correct: 4112 #Trained: 5001 Training Accuracy: 82.22 % Progress: 25.00 % Speed(reviews/sec): 666.67 Error: [-0.118178] #Correct: 4925 #Trained: 6001 Training Accuracy: 82.07 % Progress: 29.17 % Speed(reviews/sec): 777.78 Error: [-0.260138] #Correct: 5758 #Trained: 7001 Training Accuracy: 82.25 % Progress: 33.33 % Speed(reviews/sec): 888.89 Error: [-0.20240952] #Correct: 6590 #Trained: 8001 Training Accuracy: 82.36 % Progress: 37.50 % Speed(reviews/sec): 900.00 Error: [-0.33177588] #Correct: 7428 #Trained: 9001 Training Accuracy: 82.52 % Progress: 41.67 % Speed(reviews/sec): 1000.00 Error: [-0.38912057] #Correct: 8276 #Trained: 10001 Training Accuracy: 82.75 % Progress: 45.83 % Speed(reviews/sec): 1100.00 Error: [-0.26656737] #Correct: 9113 #Trained: 11001 Training Accuracy: 82.84 % Progress: 50.00 % Speed(reviews/sec): 1200.00 Error: [-0.24639801] #Correct: 9953 #Trained: 12001 Training Accuracy: 82.93 % Progress: 54.17 % Speed(reviews/sec): 1300.00 Error: [-0.25407967] #Correct: 10813 #Trained: 13001 Training Accuracy: 83.17 % Progress: 58.33 % Speed(reviews/sec): 1272.73 Error: [-0.09205417] #Correct: 11658 #Trained: 14001 Training Accuracy: 83.27 % Progress: 62.50 % Speed(reviews/sec): 1363.64 Error: [-0.33561732] #Correct: 12484 #Trained: 15001 Training Accuracy: 83.22 % Progress: 66.67 % Speed(reviews/sec): 1454.55 Error: [-0.25248647] #Correct: 13309 #Trained: 16001 Training Accuracy: 83.18 % Progress: 70.83 % Speed(reviews/sec): 1545.45 Error: [-0.17532308] #Correct: 14150 #Trained: 17001 Training Accuracy: 83.23 % Progress: 75.00 % Speed(reviews/sec): 1636.36 Error: [-0.06026015] #Correct: 15002 #Trained: 18001 Training Accuracy: 83.34 % Progress: 79.17 % Speed(reviews/sec): 1583.33 Error: [-0.96510939] #Correct: 15874 #Trained: 19001 Training Accuracy: 83.54 % Progress: 83.33 % Speed(reviews/sec): 1666.67 Error: [-0.12708723] #Correct: 16732 #Trained: 20001 Training Accuracy: 83.66 % Progress: 87.50 % Speed(reviews/sec): 1750.00 Error: [-0.11112597] #Correct: 17603 #Trained: 21001 Training Accuracy: 83.82 % Progress: 91.67 % Speed(reviews/sec): 1833.33 Error: [-0.26326772] #Correct: 18456 #Trained: 22001 Training Accuracy: 83.89 % Progress: 95.83 % Speed(reviews/sec): 1916.67 Error: [-0.33464499] #Correct: 19311 #Trained: 23001 Training Accuracy: 83.96 % Training Time: 0:00:13.196065
sentimental.test(x_test, y_test)
Progress: 0.00% Speed(reviews/sec): 0.00 #Correct: 0 #Tested: 1 Testing Accuracy: 0.00 % Progress: 10.00% Speed(reviews/sec): 0.00 #Correct: 85 #Tested: 101 Testing Accuracy: 84.16 % Progress: 20.00% Speed(reviews/sec): 0.00 #Correct: 172 #Tested: 201 Testing Accuracy: 85.57 % Progress: 30.00% Speed(reviews/sec): 0.00 #Correct: 263 #Tested: 301 Testing Accuracy: 87.38 % Progress: 40.00% Speed(reviews/sec): 0.00 #Correct: 341 #Tested: 401 Testing Accuracy: 85.04 % Progress: 50.00% Speed(reviews/sec): 0.00 #Correct: 431 #Tested: 501 Testing Accuracy: 86.03 % Progress: 60.00% Speed(reviews/sec): 0.00 #Correct: 515 #Tested: 601 Testing Accuracy: 85.69 % Progress: 70.00% Speed(reviews/sec): 0.00 #Correct: 589 #Tested: 701 Testing Accuracy: 84.02 % Progress: 80.00% Speed(reviews/sec): 0.00 #Correct: 660 #Tested: 801 Testing Accuracy: 82.40 % Progress: 90.00% Speed(reviews/sec): 0.00 #Correct: 745 #Tested: 901 Testing Accuracy: 82.69 %
This speeds it up quite a bit (at least the training), although the trade-off in accuracy might be something to watch out for. But in some cases the speed-up will help either to run the model or to use bigger data-sets. In fact, if we had a larger data set it's entirely possible that the trade-off would be worth it.