Org-Babel Cheat Sheet
Keyboard Shortcuts
Code Block Shortcuts
| Keys | Command | Effect |
|---|---|---|
C-c C-c |
org-babel-execute-src-block |
Execute the code in the current block. |
C-c ' |
Open/close edit-buffer with mode set to match the code-block language. | |
C-c C-v C-z |
org-babel-switch-to-session |
Open a python/ipython console (only works with :session) |
Buffer-wide Shortcuts
| Keys | Command | Effect |
|---|---|---|
<s Tab |
Create a code block. | |
C-c C-v C-b |
org-babel-execute-buffer |
Execute all code blocks in buffer. |
C-c C-v C-f |
org-babel-tangle-file |
Tangle all blocks marked to :tangle |
C-c C-v C-t |
org-babel-tangle |
Seems like an alias for tangle file… |
Code Block Headers
This is the subset of headers/header values that I'm interested in right now.
Code to tangle
The pattern I use to tangle (create an external code file) is:
pythonas the language (since I'm not using it with an interactive session, no need for ipython):noweb tangleis turned on frominit.elso that I can substitute code defined elsewhere into the block:tangle <path to file>
#+begin_src python :tangle literate_python/literate.py
"""A docstring for the literate.py module"""
# imports
import sys
<<literate-main-imports>>
# constants
# exception classes
# interface functions
# classes
<<LiterateClass-definition>>
# internal functions & classes
<<literate-main>>
if __name__ == "__main__":
status = main()
sys.exit(status)
#+end_src
Since I have :noweb tangle set, the substitions (e.g. <<literate-main-imports>>) don't get expanded in HTML/Latex output (although they do when you create the python file).
"""A docstring for the literate.py module"""
# imports
import sys
<<literate-main-imports>>
If you want to show the substitutions when exporting use :noweb yes in the header.
"""A docstring for the literate.py module"""
# imports
import sys
A named section
The noweb substitution above (<<literate-main-imports>>) worked because there was a named-section (defined here) that it could use:
#+name: literate-main-imports
#+begin_src python
from argparse import ArgumentParser
#+end_src
Update
I now prefer to use :noweb-ref in the header instead of the separate #+name: block.
#+begin_src python :noweb-ref literate-main-imports
from argparse import ArgumentParser
#+end_src
Results
The :results header argument declares how to handle what's returned from executing a code block. There are three classes of arguments and you can use up to one of each in the header.
Result Classes
| Class | Meaning |
|---|---|
| collection | How the results should be collected if there's multiple outputs. |
| type | Declare what type of result the code block will return. |
| handling | How should results be handled. |
Collection Class
| Option | Meaning |
|---|---|
| value | (Default) Uses the value of the last statement in the block (python requires a return statement) |
| output | (:results output) Collects everything sent to stdout in the block. |
Type Class
| Option | Example | Meaning |
|---|---|---|
| table | :results value table |
Return an org-mode table (vector) |
| scalar | :results value scalar |
Return exactly the value returned (string) |
| file | :results value file |
Return an org-mode link to a file |
| raw | :results value raw |
Return as org-mode command |
| html | :results value html |
Expect contents for #+begin_html |
| latex | :results value latex |
Expect contents for #+begin_latex |
| code | :results value code |
Expect contents for #+begin_src |
| pp | :results value pp |
Expect code and pretty-print it |
Handling Class
| Option | Example | Meaning |
|---|---|---|
| silent | :results output silent |
Don't output in org-mode buffer |
| replace | :results output replace |
(Default) Overwrite any previous result |
| append | :results output append |
Append output after any previous output |
| prepend | :results output prepend |
Put output above any previous output |
Exports
This argument tells org-babel what to put in any exported HTML or Latex files.
| Option | Example | Meaning |
|---|---|---|
| code | :exports code |
(default) The code in the block will be included in the export. |
| results | :exports results |
The result of evaluating the code will be included. |
| both | :exports both |
Include code and results in the file. |
| none | :exports none |
Don't include anything in the file. |
Running Tests
Say there was another section in the document that tangled a test-file (named testliterate.py) to test our main source file. Once both are tangled you can run it in the document using sh as the language. The org-mode documentation shows a more complex version of this which builds a pass-fail table, but that's beyond me right now.
#+name: shell-run-pytest
#+begin_src sh :results output :exports both
py.test -v literate_python/testliterate.py
#+end_src
============================= test session starts ============================== platform linux -- Python 3.5.1+, pytest-3.0.5, py-1.4.32, pluggy-0.4.0 -- /home/cronos/.virtualenvs/nikola/bin/python3 cachedir: .cache rootdir: /home/cronos/projects/nikola/posts, inifile: plugins: faker-2.0.0, bdd-2.18.1 collecting ... collected 1 items literate_python/testliterate.py::test_constructor PASSED =========================== 1 passed in 0.06 seconds ===========================
Specific Block Cases
Plant UML
Besides setting the language to plantuml you need to specify and output-file path and set :exports results so that the actual plantuml code won't be in the exported document but the diagram will.
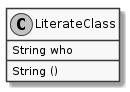
#+begin_src plantuml :file literate_python/literateclass.png :exports results
skinparam monochrome true
LiterateClass : String who
LiterateClass : String ()
#+end_src
ob-ipython
The main thing to remember for ob-ipython is that you need to run it as a :session. I didn't do it for most of the examples, but I've found since I first wrote this that using named sessions makes it a lot easier to work. Otherwise you might have more than one buffer with an org-babel document and they will be sharing the same ipython process, which can cause mysterious errors.
#+begin_src ipython :session session1
# python standard library
import os
#+end_src
When using pandas most of the methods produce values, but the info method instead prints to stdout so you have to specify this as the :results or it will popup a separate buffer with the output.
#+begin_src ipython :session session1 :results output
housing.info()
#+end_src
When you create figures, besides making sure that you use the %matplotlib inline magic, you also need to specify a file path where matplotlib can save the image.
#+BEGIN_SRC ipython :session session1 :file "images/ocean_proximity_count.png"
figure = seaborn.countplot(x="ocean_proximity", data=housing)
#+end_src
Set Up
Dependencies
I'm using ob-ipython to use jupyter/ipython with org-babel so you have to install it (I used MELPA). In addition you need to install the python dependencies, the main ones being ipython and jupyter. Additionally, I use elpy (also from MELPA) which has its own dependencies. I think the easiest way to check and see what elpy dependencies you need is to install elpy (there's two components, an emacs one you install from melpa and a python component you install from pip) then run M-x elpy-config to see what's missing.
init.el
Since I mentioned ob-ipython and elpy I'll list what I have in my init.el file for elpy and org-babel.
Elpy
;; elpy
(elpy-enable)
(setq elpy-rpc-backend "jedi")
(eval-after-load "python"
'(define-key python-mode-map "\C-cx" 'jedi-direx:pop-to-buffer))
(elpy-use-ipython)
org-babel
;; org-babel
;;; syntax-highlighting/editing
(add-to-list 'org-src-lang-modes '("rst" . "rst"))
(add-to-list 'org-src-lang-modes '("feature" . "feature"))
;;; languages to execute/edit
(org-babel-do-load-languages
'org-babel-load-languages
'((ipython . t)
(plantuml . t)
(shell . t)
(org . t)
;; other languages..
))
;;; noweb expansion only when you tangle
(setq org-babel-default-header-args
(cons '(:noweb . "tangle")
(assq-delete-all :noweb org-babel-default-header-args))
)
;;; Plant UML diagrams
(setq org-plantuml-jar-path (expand-file-name "/usr/share/plantuml/plantuml.jar"))
;;; execute block evaluation without confirmation
(setq org-confirm-babel-evaluate nil)
;;; display/update images in the buffer after evaluation
(add-hook 'org-babel-after-execute-hook 'org-display-inline-images 'append)